.png)
Execution Is the New Strategy: What Top Leaders at Fresh Gravity Are Doing Differently
December 23rd, 2025 WRITTEN BY FGadmin

Written by Sonali Kulkarni, Sr. Manager, People & Talent
In leadership conversations, there is a long-standing belief that senior leaders should focus on strategy — the what — while delegating the how to their teams. Vision, direction, and resource allocation are considered “top-of-the-house” priorities, while operational workflows are left to managers and frontline employees.
But at Fresh Gravity, we have a different approach. The success of Fresh Gravity is led by executives and directors who are deeply engaged in how work actually gets done — not by micromanaging, but by shaping the systems, practices, and behaviors that drive everyday execution.
This leadership style, often termed “hands-on leadership,” has played a pivotal role in our sustained success.
So, what sets hands-on leaders apart?
- Focusis relentlessly onwhat clients value
Our hands-on leaders define success using metrics that matter to clients — not just internal dashboards. They ensure their units/teams deliver on what clients truly care about: speed, quality, consistency, value. This sharpens priorities and embeds an external focus into daily decision-making.
- They Architect How Work Gets Done
Rather than treating processes as tactical details, our leaders actively design and refine workflows, structures, and decision pathways. They create systems that empower teams to work efficiently and autonomously, ensuring that excellence is baked into how Fresh Gravity operates.
- They Use Experiments and Data to Drive Decisions
Hierarchy takes a back seat. Instead of relying on authority or intuition, our hands-on leaders encourage experimentation, measurement, and iteration. They create a culture where data guides decisions and failures become opportunities for continuous learning and improvement.
- They Lead by Teaching, Not Just Directing
Instead of issuing instructions from the sidelines, our hands-on leaders roll up their sleeves and teach teams the tools, methods, and principles required to execute at a high standard. Their leadership is rooted in mentorship — showing people how to do things better, not simply telling them to.
- They Build a Habit of Continuous Improvement
For our leaders, improvement is not a once-a-year initiative — it is a daily discipline. They champion a culture of “better, faster, and scalable” by driving small, consistent enhancements that, over time, create a compounding advantage competitors find difficult to match.
I can confidently say this approach truly works for Fresh Gravity. Hands-on leaders ensure that great strategies do not get lost in execution. By staying close to the work, they remove friction, clarify priorities, and address problems early. Clear systems and shared expectations empower teams to make confident, consistent decisions. A culture of experimentation accelerates learning and enables the organization to evolve more effectively. And when excellence is built into systems—not reliant on individuals—the organization continues to thrive, regardless of leadership changes.
What This Means for Today’s Leaders
For leaders in any function — including HR, operations, engineering, technology, and business — hands-on leadership provides a powerful blueprint:
- Be curious about how work gets done.
- Help teams build better systems instead of fixing problems reactively!
- Turn coaching into a daily habit.
- Use data and experimentation to steer decisions.
- Promote continuous improvement over one-time transformation programs.
Above all, hands-on leadership is not about control. It is about enabling excellence — thoughtfully, intentionally, and consistently.
In a world where execution differentiates winners from the rest, leaders who understand and shape the how are poised to build organizations that adapt faster, deliver better, and outperform for the long term.
A Unified Graph Approach for the Next Era of Intelligent Systems
December 17th, 2025 WRITTEN BY FGadmin Tags: enterprise AI, hybrid architecture, intelligent systems, unified graph approach

Written by Soumen Chakraborty, Vice President, Artificial Intelligence
During a recent Life Sciences data modernization workshop, a VP paused and asked:
“Should we use RDF or a Property Graph? Which one works better for AI and agentic workflows?”
We hear this question all the time.
But the real issue is not choosing one over the other — it’s the assumption that they serve the same purpose.
- RDF and LPG solve fundamentally different problems
- AI behaves differently with each
- No production-grade AI system uses either in isolation
After delivering ontology-driven extraction, lineage systems, record-level DQ agents, and protocol-mining pipelines, one truth is clear:
Modern enterprise AI requires a hybrid of RDF, LPG, ontologies/schemas, and vector grounding.
This blog clarifies where each fits — with real examples, not theory.
-
The Two Graph Families in Practice
RDF (Resource Description Framework)
RDF is the semantic layer — designed for meaning, rules, and governance. It represents knowledge as triples:
(Study123 — hasTrialPhase — Phase3)
RDF excels when enterprises need:
-
- Standard terminology
- Regulatory clarity
- Precise definitions
- Machine-understandable meaning
- Validation via SHACL
- Explainability
Where Fresh Gravity Used RDF: Protocol Mining & Document Digitizer
For a Life Sciences client, our ontology (RDF + OWL) is defined:
-
- What a Protocol, Arm, Cohort, Endpoint, and Procedure actually mean
-
- How do the Study Design elements relate
-
- Which metadata fields are mandatory
-
- How extracted entities must be validated
RDF did not extract text on its own — schemas, and AI did that. But RDF ensured the extracted entities were:
-
- Consistent
- Valid
- Semantically aligned
- Explainable
RDF gave us the meaning. AI + schema gave us close to 100% accurate extraction.
LPG (Labelled Property Graph)
LPG is the operational layer — optimized for:
-
- High-speed traversal
- Relationship intelligence
- Pattern discovery
- Graph analytics
- Fraud-like behavior
- Identity linking
Nodes and edges can carry properties:
(Patient456 {age:72}) —[filedClaim]-> (Claim9823)
Where Fresh Gravity Used LPG: Identity Resolution & Record-Level Lineage
Identity Resolution
For a data stewardship program, LPG enabled us to:
-
- Detect clusters of duplicate patients
- Traverse millions of edges
- Identify hidden connections in seconds
Record-Level Identity Lineage
For another client, LPG allowed us to:
-
- Trace every “data hop” or transformation
- Explore lineage metadata across dozens of pipelines
- Uncover indirect dependencies
- Pinpoint the exact upstream sources affecting a record
This level of traversal is complicated with RDF, but LPG handled it effortlessly.
-
Important Reality Check: Graphs Alone Don’t Stop Hallucination or Improve Extraction
Some AI blogs (- even GPT models) claim:
“Use an ontology/graph and hallucinations disappear.”
That is not true in practice (at least for the current generation of models as of this writing).
Across our implementations, three facts consistently hold:
Fact 1 — Schema-driven extraction is more reliable than ‘only’ ontology/graph-driven extraction
LLMs respond far better to:
-
- Structured JSON schemas
- Output templates
- Examples
- Field definitions
Ontologies enrich extraction but rarely improve raw extraction accuracy by themselves.
Document Digitizer uses:
-
- Schemas → for extraction
-
- RDF/OWL → for classification, consistency, validation
Fact 2 — Vector databases (VDB) are essential for grounding
LLMs do not efficiently query ontologies or graphs directly.
We rely on:
-
- Vector embeddings
- Hybrid retrieval
- Chunk-level semantic search
- Ontology-backed disambiguation
VDB ≠ RDF ≠ LPG — each solves a different grounding need.
Fact 3 — AI needs a multi-layered approach
A mature enterprise AI stack uses:
-
- Schemas → structure
- Ontologies (RDF/OWL) → meaning
- LPG → relationship intelligence
- Vector DB → grounding
- Agents & Tools (with LLMs/SLMs) → orchestration
Graphs are powerful — but only part of the system.
-
When Should You Use What?
Use RDF when you need:
-
- Semantic consistency
- Domain meaning
- Controlled vocabularies
- Lineage semantics
- Rule validation (SHACL)
- Regulatory auditability
Example:
Validating Clinical Trial metadata.
Use LPG when you need:
-
- Fast traversal
- Relationship patterns
- Fraud-like detection
- Dynamic 360 views
- Deduplication & linking
- Impact exploration at scale
Example:
Detecting duplicate patient entities across millions of rows.
Use BOTH when you need:
-
- AI-ready hybrid Knowledge Base, semantic + operational lineage
Example:
RDF (via OWL) defined:
- AI-ready hybrid Knowledge Base, semantic + operational lineage
“A Form must belong to one Submission.”
“A Submission must reference ≥ 1 Report.”
LPG answered real questions:
“If variable X changes, which forms break?”
“Which downstream submissions are impacted?”
“Which datasets feed those forms?”
-
- End-to-end explainability
- Scalable data quality and data governance workflows
- Mapping + rule enforcement + traversal
Which, honestly… is what every enterprise wants today.
-
The Future: Agentic AI Needs Meaning + Relationships + Retrieval
AI agents operating on enterprise data need to:
-
- Enforce semantic rules (RDF + SHACL)
- Understand domain meaning (OWL)
- Analyze relationships efficiently (LPG)
- Detect anomalies & duplicates (LPG)
- Retrieve grounding context (Vector DB)
- Maintain traceability (RDF + lineage)
Every successful FG delivery has followed this pattern:
-
- RDF for meaning
- LPG for relationship intelligence
- Schemas for extraction
- Vectors for grounding
- AI/LLMs for reasoning
- Agents for automation
This is what modern enterprise AI actually looks like.
Final Thoughts
If your team is debating:
“RDF vs LPG — which one should we choose?”
You’re asking the wrong question.
The real question is:
“Where do we need semantic meaning and constraint-based reasoning?
Where do we need fast traversal and operational insight?
And how will our AI agents orchestrate schemas, vectors, RDF, and LPG together?”
At Fresh Gravity, we stopped guessing.
We built. We delivered. What consistently works is a hybrid, purpose-driven architecture for enterprise AI.
Listening to Empower: The Fresh Gravity Way
November 17th, 2025 WRITTEN BY FGadmin Tags: employee centric, Employee engagement, our work culture

Written by Nital Sawde, Sr. Specialist, People & Talent
At Fresh Gravity, we believe that our people are at the heart of everything we do. Every innovation, every idea, and every achievement begins with the passion and commitment of our team members. Yet, one of the most powerful contributors to Fresh Gravity’s success isn’t just what we communicate to our people or ask them to do, but it’s how deeply we listen to them.
Our culture is such that we strongly believe that a happy team leads to happy clients.
Hence, we ensure to gather feedback from employees. It is more than collecting opinions; it’s about understanding experiences, building trust, and creating an environment where everyone feels valued and heard.
The feedback we gather serves as a bridge between leadership and employees, helping us see the organization through the eyes of those who live its values every day. At Fresh Gravity, we encourage open and honest dialogue — whether through surveys, one-on-one connects, or informal conversations — because listening is the first step toward learning and improving.
We believe feedback fuels both engagement and satisfaction. While closely connected, these two come from distinct experiences:
Employee satisfaction reflects how content employees feel with their role, work environment, and leadership support.
Employee engagement goes further; it’s about how emotionally and intellectually invested they are in contributing to the company’s success.
When we act on feedback — by improving policies, enhancing communication, or refining processes — employees see that their voices lead to real change. This not only boosts satisfaction but also cultivates a strong sense of ownership, pride, and empowerment.
Key Stages Where Employee Feedback Is Gathered
-
Onboarding Stage
Purpose: To understand the new joiner’s initial experience and identify onboarding gaps.
Focus Areas:
-
- Clarity of role and responsibilities
-
- Support from the onboarding team
-
- Access to tools, resources, and information
-
- First impressions of company culture
-
Probation Feedback
Purpose: To capture the early journey experience and ensure alignment of expectations.
Focus Areas:
-
- Quality of induction and training
-
- Role clarity and workload
-
- Manager and team support
-
- Integration into company culture
-
- Inclusiveness in the project and the project team
-
Performance Review Stage
Purpose: To facilitate two-way feedback between managers and employees during goal setting and appraisal cycles.
Focus Areas:
-
- Goal clarity and performance expectations
-
- Opportunities for skill development
-
- Manager support and recognition
-
- Suggestions for team or process improvement
-
Engagement Surveys
Purpose: To measure overall satisfaction and engagement across the organization.
Focus Areas:
-
- Workplace culture and communication
-
- Leadership effectiveness
-
- Career growth and learning opportunities
-
- Work-life balance and well-being
-
Leaders as Listeners
Purpose: To create space for open dialogue.
At Fresh Gravity, our leaders are active listeners. Through our “Leadership Connects” sessions, they meet with small groups of employees every quarter to understand their challenges, gather improvement ideas, and discuss these insights in Executive Meetings to shape future strategies.
This kind of leadership strengthens relationships, enhances collaboration, and inspires people to bring their best selves to work every day.
-
Exit Interviews
Purpose: To gather honest feedback from departing employees to identify trends that may impact retention.
Focus Areas:
-
- Reasons for leaving
-
- Manager and leadership experience
-
- Work culture and team dynamics
-
- Suggestions for improvement
-
Ad-hoc/Open Feedback Channels
Purpose: To encourage continuous dialogue beyond formal feedback cycles.
Examples:
-
- HR connects, skip-level meetings, or pulse check-ins
-
- Anonymous suggestion boxes or digital feedback tools
-
- One-on-one discussions with managers
Conclusion
At Fresh Gravity, feedback isn’t a one-time activity — it’s an ongoing conversation. By valuing every voice, we continue to shape a workplace where people feel empowered, heard, respected, and inspired to grow.
Because when we listen to our people, we don’t just improve processes — we strengthen our culture.
And that’s what keeps Fresh Gravity moving forward — together.
Transparent Policy Centers: Building Trust Through Governed Data Access
October 28th, 2025 WRITTEN BY FGadmin Tags: data governance, transparent policy center, unify data policies

Written by Neha Sharma, Sr. Manager, Data Management
In today’s data-driven landscape, governance without transparency is like navigation without a map. As organizations strive to strike a balance between agility and control, Transparent Policy Centers are emerging as a powerful framework to unify data policies, enforce governance, and empower business users simultaneously.
But what does transparency in policy governance really look like? And how can we make it actionable across modern data stacks?
What Is a Transparent Policy Center?
A Transparent Policy Center is a centralized, accessible interface that allows teams to:
- Document and publish data policies (access, classification, retention, etc.)
- Translate policies into business-friendly language
- Connect policies to actual data assets, users, and systems
- Track adherence, violations, and policy-related activity
The goal? Make governance understandable, actionable, and trusted — not just enforced.
Why Organizations Are Investing in It
Traditional policy management often falls short:
- Access controls are opaque — users don’t know why access is denied
- Policies are scattered across PDFs or SharePoint folders
- Manual enforcement creates bottlenecks and inconsistencies
- Audits become stressful fire drills instead of smooth validations
A Transparent Policy Center shifts governance from a backstage function to a visible, user-aware service.
Core Capabilities of a Transparent Policy Center
Whether custom-built or powered by a governance platform, a well-designed Policy Center should offer:
- Central Policy Catalog
- Consolidates all policies (e.g., data usage, privacy, classification)
- Organized by domain, region, or compliance framework
- Business-Friendly Policy Views
- Explains rules in non-technical language for analysts and stakeholders
- Highlights the “why” and “how” behind each rule
- Policy-to-Data Mapping
- Shows which tables, dashboards, or APIs are governed by each policy
- Visualizes policy impact using lineage and usage metadata
- Live Enforcement Integration
- Embeds with access control tools, data catalogs, and pipeline orchestration tools
- Captures real-time violations or policy conflicts
- Access Request & Escalation Workflow
- Users can request access with full visibility into approval paths
- Tracks status, SLAs, and owner accountability
Who Benefits from Transparent Policy Centers?
Stakeholder |
Benefits |
| Data Consumers | Understand access rules before hitting blockers |
| Stewards | Apply governance with clarity and context |
| Compliance Teams | Gain visibility into policy status and adherence |
| Executives | See governance metrics that support risk and trust initiatives |
How to Build a Transparent Policy Center
You don’t need to start from scratch — most modern data stacks already have the building blocks. Key enablers include:
- A metadata management platform (catalog or fabric)
- Policy modeling and documentation templates
- Lineage, classification, and usage tracking tools
- UI/UX layer that surfaces policies at point-of-use (e.g., within BI tools or data request portals)
- Integration with access control and ticketing systems (e.g., identity providers, JIRA, ServiceNow)
Example Use Cases
Transparent Policy Centers become invaluable across industries:
- Healthcare – Clarify HIPAA-based access to patient data
- Banking – Display BCBS 239-aligned policies on risk data
- Retail – Govern product metadata usage across systems
- Global Enterprises – Show GDPR/CCPA impact on customer attributes
Looking Ahead: Transparent, Trusted, and Autonomous
As AI begins to assist in governance, transparency becomes even more critical. Future-ready Policy Centers will:
- Flag policy conflicts or violations in real time
- Suggest owners or reviewers based on activity metadata
- Enable explainability for AI-driven policy enforcement
- Serve as a system of record for audits and trust scoring
How Fresh Gravity Can Help
At Fresh Gravity, we help enterprises design and implement Transparent Policy Centers that are:
- Aligned with business goals and compliance mandates
- Integrated with metadata, catalog, and access platforms
- Augmented with automation and stewardship intelligence
- Designed for adoption across both technical and business users
We work with leading data platforms and tailor solutions to your stack — whether you’re using Snowflake, Databricks, Informatica, Alation, or others.
Ready to Make Data Governance Transparent?
Let’s move governance from a black box to a shared, trusted, and automated experience.
Reach out at www.freshgravity.com/contact-us/
A Master Data-Led Approach to CMC Data Strategy
October 9th, 2025 WRITTEN BY FGadmin

Written By Preeti Desai, Sr. Manager, Client Success and Colin Wood, Strategy & Solutions Leader, Life Sciences
In the previous blog, we established that we can no longer afford to treat CMC data as something created just for submissions. This data holds immense operational and strategic value for analytics, process optimization, and automated regulatory submissions. But to unlock that value, data quality and structure are paramount.
We also looked at how implementing a CMC data model — a foundational framework that organizes and links entities such as materials, manufacturing processes, test methods, and experiments transforms fragmented information into an integrated system of scientific truth
There’s growing enthusiasm in pharma to apply ontologies to CMC (Chemistry, Manufacturing, and Controls) and regulatory data, and for good reason. Ontologies can bring semantic meaning, relationships, and machine-readability to data models. But attempting to use ontologies to cleanse and standardize legacy data is often misguided and inefficient.
Anyone who’s dealt with legacy data knows how messy it can be:
- If the material code starts with ‘TMP’, it was temporary and might not be valid
- Between 2020–2022, we used different naming conventions
- Batch numbers used to include site codes, but now they don’t
These kinds of inconsistent business rules are often undocumented, approximated, and full of edge cases.
Now imagine trying to model all that historical inconsistency into an ontology. You’d have to:
- Capture every exception, outdated meaning, and local rule
- Maintain conflicting definitions and overlapping hierarchies
- Build logic that explains how things used to be, not just how they should be
This quickly becomes unmanageable and defeats the purpose of ontologies, which are meant to add clarity and meaning, not capture legacy confusion.
In an era where life sciences organizations are increasingly turning to knowledge graphs, ontologies, and semantic data layers to drive digital transformation, a foundational truth is often overlooked: You cannot infer meaning from data that lacks structural and referential integrity.
When it comes to structuring CMC data, the two most essential pillars are:
- A Blueprint: A data model that defines entities, relationships, and constraints
- A Backbone: A governing Master Data Management (MDM) system that ensures the reliability and consistency of that data across sources and lifecycles
Data Model Without MDM Is an Incomplete Scaffold
A data model is the abstraction of your CMC domain. It defines:
- What entities exist (e.g., Batch, Manufacturing Process Step, Test, Stability Study)
- What attributes they hold (e.g., batch expiry date, test name, manufacturing site code, stability study start date)
- How they relate (e.g., a drug product is a formulation composed of ingredients, which are substances, manufactured at specific sites)
But in practice, even the most elegant data model fails without high-quality data that populates it, which is where MDM comes in.
Without MDM:
- Entity uniqueness is compromised — e.g., the same material could be listed under 5 different names
- Hierarchy and versioning are ambiguous — e.g., which version of a manufacturing process step applies to which submission
- Data provenance is unclear — e.g., is the acceptance criteria for pH range sourced from R&D specs or commercial process validation
A model without governed data is like a periodic table filled with scribbles. The structure is there, but the contents are unreliable, so no inference can be made.
Why MDM Without a Data Model Leads to Confusion and Data Debt
On the flip side, deploying MDM without a foundational data model turns your MDM into a glorified data registry — a collection of fields with no semantic or structural consistency.
Let’s take an example:
Suppose you’re managing “Packaged Medicinal Product” as a master data domain. Without a model, this could be:
- A free-text field in ELN
- A picklist in SAP
- A coded term in a regulatory XML schema
- A synonym list held in a reference data system
Without a model defining the context and relationships — i.e., how Packaged Medicinal Product relates to Manufactured Item, Pharmaceutical Product, strength, route of administration, container, your MDM becomes disconnected fragments rather than a unified source of truth.
MDM provides governance. The data model provides structure for the data and allows business meaning to be assigned to each entity and attribute.
They are co-dependent — not optional.
Only when these two are in place does the third layer — ontologies and knowledge graphs — can begin to generate value. This delivers semantic meaning for the data, allowing richer insights to be inferred from the data.
The next blog in the series will highlight the growing importance of IDMP in the CMC data model with the recent ICH M4Q updates. We will also cover how organizations can confidently begin layering semantic technologies such as ontologies and knowledge graphs to unlock new capabilities in automation, compliance, and analytics. Stay tuned!
Beyond the Hype: Why Data Management Needs Smaller, Smarter AI Models
October 6th, 2025 WRITTEN BY FGadmin Tags: data management, smarter AI models

Written by Soumen Chakraborty, Vice President, Artificial Intelligence
Introduction
Over the past two years, Large Language Models (LLMs) have dominated the AI conversation. From copilots to chatbots, they’ve been positioned as the universal answer to every problem. However, as enterprises begin to apply them to their data management problems, the cracks are starting to show – high costs, scalability issues, and governance risks.
At Fresh Gravity, we’ve been asking a simple question: Do you really need a billion-parameter model to validate a single record, reconcile a dataset, or generate a SQL query?
Our conclusion: not always. In fact, for many of the toughest data management challenges, smaller, task-focused models (SLMs/MLMs) are often a better fit.
The Limits of LLMs in Data Management
LLMs are brilliant at broad reasoning and open-ended generation. However, when applied to day-to-day row/column-level data management, three major issues emerge:
- Cost Explosion: Running LLMs on millions of record-level checks quickly becomes unaffordable
- Scalability Problems: They’re optimized for rich reasoning, not for repetitive, structured operations
- Governance Risks: Hallucinations or inconsistent outputs can’t be tolerated in regulated industries
That’s why betting everything on LLMs is not a sustainable strategy for enterprise data.
Why Smaller Models Make Sense
Small and Medium Language Models (SLMs/MLMs) offer a different path. They don’t try to solve every problem at once, but instead focus on being:
- Cost-efficient – affordable to run at scale
- Task-focused – fine-tuned for narrow, high-value problems
- Fast – optimized for record-level operations
- More governable – easier to constrain in compliance-heavy environments
Smaller doesn’t mean weaker. It means smarter, leaner, and more practical for the jobs that matter most.
Real Models Proving This Works
The industry already has strong evidence that smaller models can shine:
- LLaMA 2–7B (Meta): Efficient and fine-tunable, great for SQL and mapping tasks
- Mistral 7B: Optimized for speed, yet competitive with much larger LLMs
- Phi-3 (Microsoft): A 3.8B parameter model with curated training data, surprisingly good at reasoning
- Falcon 7B: Enterprise-friendly balance of performance and cost
- DistilBERT/MiniLM: Trusted for classification, entity extraction, and standardization
These models show that parameter count isn’t everything. With fine-tuning, SLMs often outperform LLMs for specific, repetitive tasks in the enterprise.
The Art of Possibility for Data Management
Now imagine what this opens for data teams:
- Models that catch bad data before it spreads, flagging missing, inconsistent, or invalid records instantly
- AI that can spin up pipelines with built-in guardrails, reducing manual coding and human error
- The ability to compare massive datasets in seconds, highlighting mismatches at scale
- Smarter matching engines that can spot duplicates across millions of records without endless rule-writing
- Query tools that let anyone turn plain English into SQL or SparkQL, putting data access in everyone’s hands
This is where smaller, focused models excel, doing the heavy lifting of data management tasks reliably, quickly, and cost-effectively
Where SLMs and LLMs Each Fit
Data Mapping
- SLMs: Handle structured, repeatable mappings (CustomerID → ClientNumber)
- LLMs: Step in when semantic reasoning is needed
- Industry Reference: Informatica CLAIRE, Collibra metadata mapping
- Fresh Gravity Example: Penguin blends SLMs for bulk mapping, escalating edge cases to LLMs
Data Observation (Monitoring)
- SLMs: Detect anomalies and unusual patterns at scale
- LLMs: Interpret unstructured logs, suggest root causes
- Industry Reference: Datadog anomaly detection + Microsoft Copilot for Security
- Fresh Gravity Example: DevOps Compass uses anomaly models + SLMs for most alerts, with LLMs reserved for complex correlations
Data Standardization
- SLMs: Normalize structured fields like dates, codes, and units
- LLMs: Resolve ambiguity in free-text or unstructured notes
- Industry Reference: Epic Systems blends AI for ICD-10 coding vs. clinical notes.
- Fresh Gravity Example: Data Stewardship Co-Pilot utilizes SLMs for structured standardization and LLMs for free-text context.
Fresh Gravity’s Hybrid Approach
We see the future as a hybrid, not one-size-fits-all. At Fresh Gravity, we’re embedding this strategy into our accelerators:
- AiDE (Agentic Data Engineering): SLMs fine-tuned on SQL/Spark for pipeline generation; LLMs for complex design tasks.
- DevOps Compass: SLMs for log parsing and anomaly detection; LLMs for deeper root cause analysis.
- Data Stewardship Co-Pilot: SLMs for reconciliation, matching, and standardization at scale; LLMs for context-heavy edge cases.
This isn’t theory — we’re running these experiments today to prove value with real-world performance and cost data.
Why Hybrid Wins
Our philosophy is simple:
- LLMs where broad reasoning is essential
- SLMs where scale, efficiency, and cost control matter most
The result is:
- Enterprise-ready scalability without runaway costs
- Predictable, fast performance for record-level tasks
- Client empowerment to deploy in the cloud or on-prem, affordably
Conclusion
LLMs have expanded the boundaries of what AI can do. But in data management, the future isn’t about “bigger models.” It’s about smarter combinations of models that fit the task at hand.
By blending the power of LLMs with the efficiency of SLMs, we can build solutions that are innovative, scalable, and sustainable.
At Fresh Gravity, that’s exactly what we’re doing: embedding hybrid AI into our accelerators so our clients don’t just chase the hype — they see real, lasting business outcomes.
Beyond the Dossier: Unlocking Strategic Value in CMC Data
September 23rd, 2025 WRITTEN BY FGadmin Tags: artificial intelligence, CMC data

Written By Preeti Desai, Sr. Manager, Client Success and Colin Wood, Strategy & Solutions Leader, Life Sciences
In the world of bio-pharmaceutical development, Chemistry, Manufacturing, and Controls (CMC) is often described as the regulatory backbone of any product submission. Yet, despite its critical role, CMC remains one of the most underutilized, least digitized, and most manually intensive areas in the product development lifecycle.
In recent years, the pharmaceutical industry has shifted focus from merely digitizing documentation to treating data as a core business asset. As regulatory expectations evolve and time-to-market pressures increase, structured CMC data is emerging as the new API — connecting R&D, manufacturing, and regulatory functions. More than just supporting faster submissions, CMC data lays the foundation that has the potential to inform accelerated drug development, enabling companies to learn from prior experiments, optimize processes, and reduce redundancy. When structured properly, this data becomes the substrate on which AI models, ontologies, large language models (LLMs), and knowledge graphs can operate, exponentially increasing its scientific and operational value.
In part one of this blog series, we will dive into the importance of leveraging CMC data and why it matters now more than ever.
CMC — and Why It is the Regulatory Backbone
CMC refers to the comprehensive set of data required by health authorities (like the FDA, EMA) to ensure the quality, safety, and consistency of a drug product. It spans the entire lifecycle — from raw materials and analytical methods to formulation, process development, and manufacturing controls.
CMC tells the technical narrative — one built on structured evidence. It proves that the product:
- Is made consistently, batch after batch
- Meets its defined specifications, every time
- Is safe and reproducible at scale, from the lab bench to the manufacturing line
It’s not just a compliance formality — it’s the foundation that gives regulators confidence, manufacturers direction, and patients trust.
Digitization in Modern CMC Submissions: The Investment Dilemma
While fully digital regulatory submissions are still several years away — with ICH M4 and related guidelines continuing to favor document-based formats — the industry’s momentum toward digitization is undeniable. This creates a dilemma for many pharmaceutical companies: Should they invest in digital infrastructure now, or wait for regulatory mandates to catch up?
Reluctance is understandable because, despite being data-rich, the CMC landscape is riddled with inefficiencies. From early-stage discovery to commercial production, teams grapple with:
|
Challenge |
Impact |
| Unstructured Documentation | Regulatory dossiers capture only the successful version of the product story, not the dozens (or hundreds) of failed experiments that informed it |
| Fragmentation across systems | Experimental data in ELNs (Electronic Lab Notebooks), training data in LMS (Learning Management Systems), analytical results live in LIMS or spreadsheets, protocols and other documents are stored across hard copies, SharePoint, email, or regulatory systems |
| Document-centric workflows | Final reports hide rich experimental context (failures, iterations, etc.). Negative data is lost, skewing success metrics. |
| Data stuck in non-machine formats | PDFs, Word files, emails; difficult for AI/ML systems to parse |
| Missing metadata & identifiers | Experiments lack standard IDs; test methods aren’t linked to parameters |
| Incomplete experimental records | Many ELN experiments are not signed off, falsely assumed as complete |
| Cultural resistance | Scientists prioritize experimentation, not metadata entry or tagging |
| No unified data model | No central data schema across formulation, process, and analytical units |
In short, CMC data exists, but it is invisible, scattered, and disconnected.
Missed Opportunities: Data Ignored Beyond Submissions
What’s often overlooked is that CMC documentation is merely a snapshot — the “final cut” of a much richer, iterative scientific process. In many organizations, once a submission is filed, the underlying data is:
- Archived and locked away
- Disconnected from future product lifecycle activities
- Ignored for cross-product learnings or platform optimization
- Unavailable for AI/ML model training or decision support systems
The future of CMC is not a better document. It’s a better data product. Companies that start treating CMC data as a core asset — not just a compliance output — will be the ones ready for the future, long before the future arrives.
The CMC Data Model – A Game Changer
AI thrives not on raw data — but on clean, structured, and semantically linked data — which is impossible without a robust data model and a strong Master Data Management (MDM) foundation. That’s what a modern CMC strategy should aim for. While digital submissions are still on the horizon, structured, traceable CMC data creates measurable value today and positions organizations to lead when the regulatory landscape inevitably evolves.
The shift toward structured, connected CMC data is more than a digital upgrade; it marks a paradigm shift in how pharmaceutical companies can derive scientific and operational intelligence across the value chain.
At the centre of this shift lies the CMC data model, a foundational framework that organizes and links entities such as materials, processes, test methods, and experiments. When implemented correctly, this model transforms fragmented information into an integrated system of scientific truth.
Discover how Fresh Gravity helps you streamline, manage, and submit this essential data with accuracy and compliance.
|
Entity |
Description |
| Materials | Raw materials, excipients, APIs — linked to suppliers, specs, test methods. Every material, method, and process parameter is traceable across trials and products. |
| Process Parameters | All critical steps, ranges, control strategies, and development history. Product development teams query the system to find which conditions led to failed batches in similar products. |
| Test Methods | Analytical methods used across stages, their validations, and associated data |
| Experiments | Each experiment ID in a submission links back to the full scientific dataset (ELN, LMS, LIMS). IDs linked to ELNs/LMS, showing both positive and negative outcomes. |
| Product Profiles | Target product quality attributes (TPPs, QTPPs), and supporting evidence |
Each entity is:
- Structured (machine-readable)
- Linked (e.g., experiment ID connects to ELN records)
- Queryable (can be filtered, aggregated, reported on)
- HL7 FHIR Aligned (supporting future digital submission standards)
This model becomes a central data hub, enabling:
- Faster submissions (Regulatory authors auto-generate sections of CTD from verified, structured data)
- Cross-functional collaboration (R&D ↔ Regulatory ↔ QA)
- AI assistants to recommend process improvements or analytical methods based on prior outcomes
Example: Tracking an Experiment ID from LIMS to Manufacturing Using a CMC Data Model
Step 1: Experiment Creation in R&D (LIMS/ELN)
- A formulation scientist runs an experiment to optimize pH and excipient concentration for a new oral solid dosage form
- The experiment is logged in LIMS and linked in ELN with a unique Experiment ID: EXP-2025-00321
- Associated data includes:
- API lot number
- Excipient types and suppliers
- Process parameters (mixing speed, granulation time, drying temperature)
- In-process control (IPC) results
- Stability data for early formulation prototypes
The CMC data model captures this under:
- Entity: Experiment
- Attributes: ID, author, timestamp, purpose, related material IDs
- Entity: Materials
- Attributes: API, excipients, batch IDs, specs
- Entity: Process Parameters
- Attributes: equipment, duration, ranges, outputs
Result: The Experiment ID becomes a unique anchor for linking structured formulation and process development data.
Step 2: Scale-Up & Manufacturing Transfer
- The optimized process is transferred to pilot-scale manufacturing.
- Key parameters from EXP-2025-00321 are used as a baseline for defining:
- CPPs (Critical Process Parameters) and
- CQA (Critical Quality Attributes)
- At this point, MES (Manufacturing Execution System) records:
- Actual process values (e.g., granulation time, drying profile)
- Equipment used
- In-process deviations
- Batch records and performance metrics
The CMC data model now links:
- Experiment ID → Pilot batch IDs → Full-scale batch IDs
- Shared materials, methods, and parameters across scales
From Data Product to Decision Engine
For the above example with EXP-2025-00321, structured CMC data linkage, the organization could explore the following use cases with the CMC data generated and linked accurately.
|
AI/Analytics Use Case |
How the CMC Data Model Enables It |
|
| Insights | How many experiments supported this target profile? What % of trials failed? Why? Where are the gaps? What’s pending sign-off? | |
| Root Cause Analysis | If a commercial batch fails, AI traces back to EXP-2025-00321 and identifies parameter drift or raw material variability | |
| Predictive Modeling | Train models using historical experiment-to-batch mappings to predict yield, dissolution, or stability outcomes | |
| Process Optimization | AI identifies which pilot-scale parameters most strongly influenced product quality and recommends adjustments | |
| Formulation Reuse | Enables scientists to query: “Which previous formulations with similar APIs succeeded under similar conditions?” | |
| LLM-Enhanced Decision Support | A language model can be prompted: “Summarize all experiments linked to pilot batch BATCH-00215 that led to stability failures.” | |
While this blog offers only a high-level overview, the data model conceptualized by Fresh Gravity is significantly more detailed and comprehensive — built to support data structure complexity, regulatory alignment, and long-term scalability. If you’d like to explore the full scope of the model and its practical applications, get in touch with us.
In the next blog, we will dive deeper into how Master Data Management (MDM) systems and IDMP-aligned reference models can enhance this vision — particularly through the lens of ICH M4Q analysis. We’ll explore how aligning M4Q elements with IDMP concepts (like pharmaceutical product, manufactured item, and packaging) creates a more robust, interoperable data model — one that can serve both compliance needs and digital innovation.
The Path to Agentic intelligent Data Engineering
September 17th, 2025 WRITTEN BY FGadmin Tags: agentic AI, AI agents, artificial intelligence, Data Engineering, improved data quality

Written by Siddharth Mohanty, Director, Data Management
Evolving Agentic AI Landscape
- Artificial intelligence (AI) is developing quickly, moving from basic assistants to self-governing systems that can act and make decisions with little human supervision.
- Generative AI, AI agents, agentic AI, and now the Model Context Protocol (MCP), a ground-breaking framework that standardizes how AI communicates with outside tools and data sources, have all been steps in this journey.
- Conventional generative AI was proficient at producing text, graphics, and code, but it lacked autonomy at its core. This gap is filled by agentic AI, which uses generative capabilities to allow for truly autonomous action.
With a keen focus on the rapidly evolving field of artificial intelligence, we, at Fresh Gravity, have created a novel approach to using AI to create dependable and scalable data engineering solutions. Our vision of a future–ready data engineering solution represents a next-generation approach to building, automating, and optimizing data workflows by leveraging LLM and AI agents to act intelligently and autonomously throughout the data lifecycle. This blog is a deep dive into one such proprietary solution built by Fresh Gravity – Agentic intelligent Data Engineering (AiDE) solution.
AI Helping Make More Data Become Better Data
With key characteristics such as autonomy, goal-oriented execution, adaptability, multi-agent collaboration and integration with tools, AI agents come power-packed to alleviate complexity and manual overhead. Key capabilities of AI Agents include:
- Operational Efficiency: Automation of repetitive processes like data entry, purification, and validation, agentic AI improves operational efficiency. Batch and live ingestion operations are coordinated through data pipeline optimization. Schemas are dynamically modified in response to patterns found. Agents maintain data integrity across systems, optimize queries for speed and cost effectiveness, and keep an eye on warehouse performance
- Increased Accuracy: By fusing the accuracy of traditional programming with the flexibility of large language models (LLMs), agentic AI can increase accuracy and precision and make better judgments depending on context and real-time data. Agents can examine large datasets, find inefficiencies in workflows, and spot anomalies without human involvement thanks to live analytics.
- Improved data quality: Via intelligent monitoring and validation. Fresh Gravity’s AiDE comes powered with Data Quality, Data Reconciliation, and Data Observability agents designed to monitor data and pipelines to detect data discrepancies. AiDE has Data Quality and Observability Dashboards OOTB, providing real-time insights
- Real-time Insights: AI agents can be designed to continuously profile incoming data, analyze patterns, offer real-time insights, and identify trends
- Optimized Performance: Agentic AI effectively manages large-scale data environments, adapting to increasing volumes and complexities Agentic AI effectively manages large-scale data environments, adapting to increasing volumes and complexities.
- Enhanced Compliance and Risk Management: This is achieved by developing models and agents to deploy policies and rules into execution. For example, we have built agents to take specific actions while processing PII data elements.
AI Agents Powering Data Engineering
Fresh Gravity’s AiDE solution accelerates the data engineering ecosystem by intelligently automating repetitive operations and providing AI-powered tools with the ability to effectively build, maintain, and improve data pipelines, thereby reducing the responsibilities of data professionals. These improvements are achieved by using AI Agents to bring efficiency gains, as listed in the earlier section, across the data engineering life cycle. These models are already proficient in debugging, optimization, and generating Python and SQL code, and their capabilities are expanding daily.
From making raw data understandable to integrating, coordinating, and automating heterogeneous data into AI operations, data engineers are now at the vanguard of the AI movement.
Fresh Gravity’s Agentic Data Engineering Solution
AI-driven Data Engineering is quickly shifting from trend to necessity, driven by the need for adaptability, speed, operational excellence, and insights at scale. By embedding intelligence throughout the data pipeline, organizations can innovate more quickly, reduce costs, mitigate risks, and lay the groundwork for the future of data-driven decision-making.
We have developed a one-of-a-kind AI-powered Data Engineering packaged solution to address all facets of a data solution (data pipelines development, data discovery, audit & control framework, data quality and reconciliation, orchestration and workflow management, data observability), Agentic intelligent Data Engineering (AiDE), an AI-powered smart and intelligent solution packaging a suite of agents performing data discovery, data ingestion, orchestration, execution, data validation, monitoring and observability.
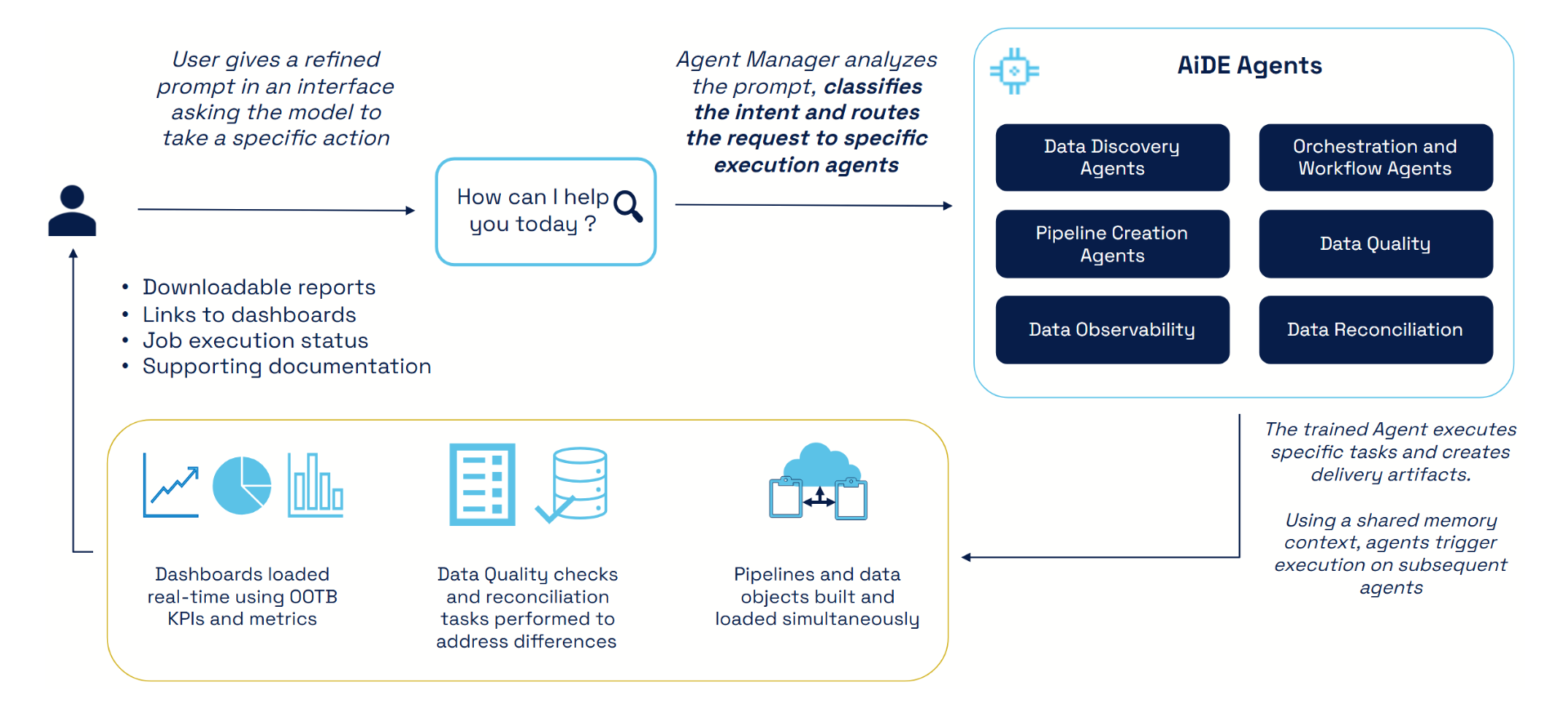
AiDE comes prepacked with code templates and coding standards with audit features enabled Out-of-The-Box (OOTB). Data Engineers can define the interfacing of source data systems with AiDE and, through a smart prompt, provide the AI model with context to discover data, develop pipelines, create audit table entries, execute pipelines, perform QC on data executions, and build operational dashboards for observability of the workload.
AiDE also comes with a Human-In-The-Loop (HITL) framework to incorporate business/domain-specific data processing logic into the pipelines. All data pipelines created with AiDE follow our in-house core design principle of a Metadata-Driven Framework (MDF), ensuring extensibility and flexibility by design for every artifact that gets delivered.
To know more about building performant data products and solutions on-premises or on cloud, please write to us at info@freshgravity.com.
From Data to Decisions: Discover ZoomInfo’s Ready-to-Use Reltio MDM Integration
September 11th, 2025 WRITTEN BY FGadmin Tags: b2b, b2c, customer data management, data enrichment, data management, data quality assurance, master data management, Reltio, RIH, ZoomInfo

Written by Ashish Rawat, Sr. Manager, Data Management
In customer data management, where data–driven business decisions are pivotal, effectively harnessing and utilizing data is a necessity. Availability of data is no longer a problem for firms, but the identification of relevant information among vast amounts of data is certainly a puzzle. To address this critical need, Fresh Gravity, in partnership with Reltio Inc. and ZoomInfo, has developed a pre-built integration between Reltio and ZoomInfo, providing seamless data enrichment of your enterprise Master Data.
Data enrichment empowers businesses to unlock the full potential of their customer data by layering in trusted insights from reliable third-party sources. Beyond simply filling gaps, enrichment adds critical attributes and relationships that transform raw records into complete, actionable profiles. In the context of Master Data Management (MDM), this process ensures organizations are working with accurate, consistent, and up-to-date information. The result is higher data quality that drives smarter business decisions, supports regulatory compliance, and enables personalized, customer-centric experiences that fuel growth and loyalty. This pre-built integration is designed and developed to enrich customer data, both for the B2B and B2C dataspace.
- The B2B dataspace encompasses critical customer information about organizations, extending far beyond basic identifiers. These datasets typically include firmographic details (such as industry, size, and location), financial metrics, corporate hierarchies, and other key attributes that provide a 360° view of a business. When structured and managed effectively, this information becomes the foundation for stronger customer insights, improved segmentation, and more informed decision-making across the enterprise.
- The B2C dataspace centers around individual consumer information, bringing together data that enables a deeper understanding of people and their behaviors. This often includes demographic details (age, gender, income, location), contact information, behavioral signals (such as purchasing patterns, digital interactions, and channel preferences), along with lifestyle and interest indicators. When managed effectively, these data points provide organizations with the insights needed to segment audiences, deliver personalized experiences, and drive stronger engagement and conversion.
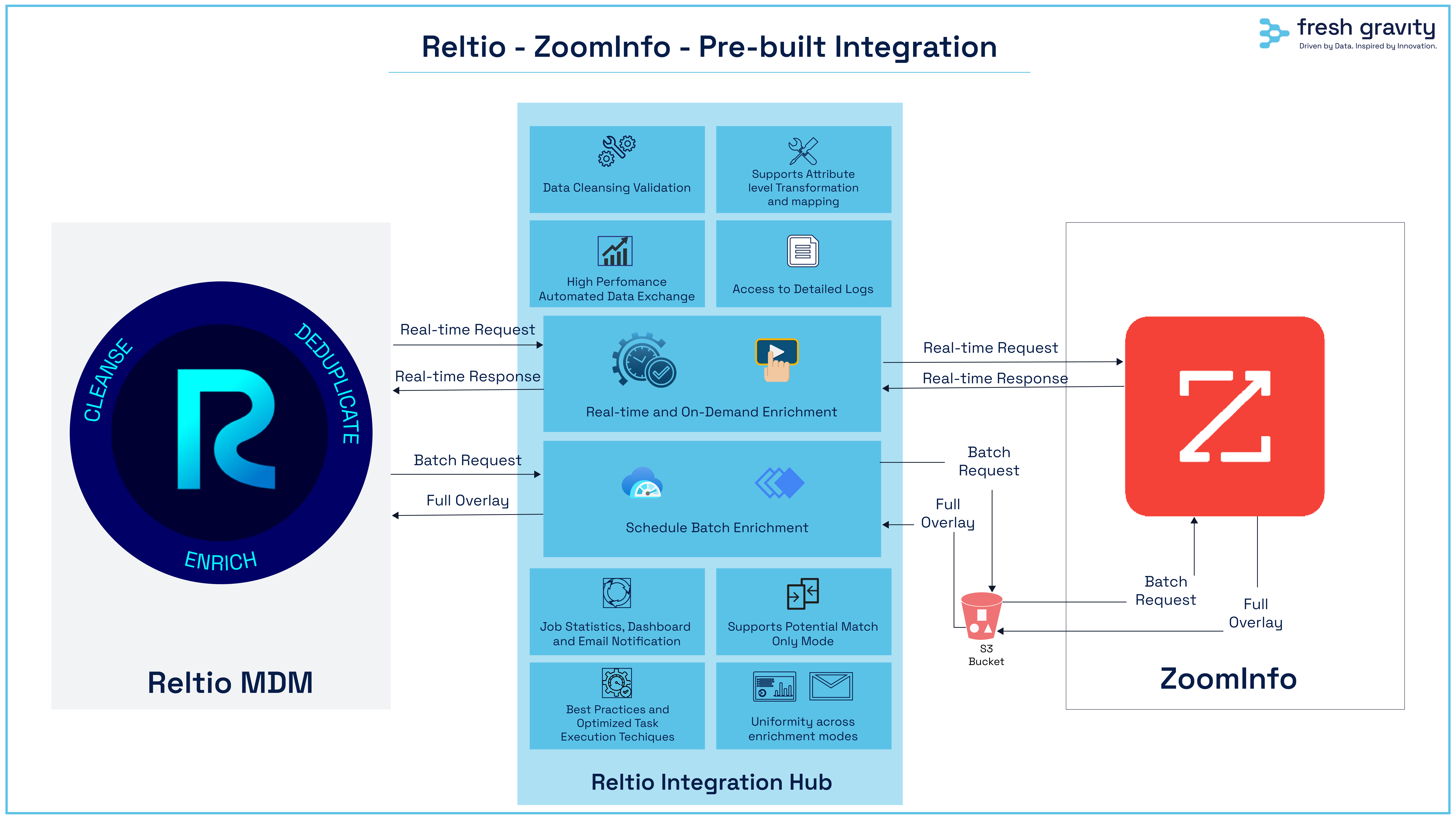
Reltio-ZoomInfo Pre-Built Integration
This integration is designed in accordance with Reltio’s Customer Data (B2B & B2C) velocity pack, which maps ZoomInfo data points to industry–specific data models. It also empowers the user to customize the integration to fulfill their business needs. This integration is built on top of Reltio Integration Hub (RIH), which is a component of the Reltio Connected Customer 360 platform.
This pre-built integration supports the following modes of data enrichment:
- Batch enrichment with a scheduler or API–based triggers
- Real–time enrichment leveraging Reltio’s integrated SQS queue
- An API–based trigger for on-demand enrichment. This can be useful for UI button-based integration
- Monitoring an automated process to ensure records registered for regular updates are constantly refreshed
Why Fresh Gravity + ZoomInfo + Reltio = Smarter Customer Data
When it comes to mastering customer data, success isn’t just about connecting systems—it’s about doing it the right way. That’s where Fresh Gravity’s expertise in Master Data Management (MDM) and our integration with ZoomInfo’s global database come together to deliver unmatched value.
Our approach is grounded in implementation best practices, ensuring every deployment is reliable and future-ready. By seamlessly connecting with ZoomInfo’s expansive and trusted dataset, organizations can enrich their records with highly accurate, comprehensive insights that fuel better decisions.
Performance is another cornerstone. With optimized RIH recipes, businesses can expect lightning-fast processing, efficient task utilization, and rock-solid reliability—even when handling high-volume data environments. And because data needs evolve as companies grow, the solution is built with scalability at its core, supporting everything from routine updates to large-scale enrichment projects.
What truly sets this integration apart is the effortless setup and smooth alignment with Reltio MDM, minimizing disruption while delivering immediate value. Once in place, users benefit from an intuitive interface that simplifies complex data operations, allowing teams to focus on insights rather than mechanics. On top of that, detailed logs, real-time statistics, and automated notifications provide complete transparency, so teams are always informed and in control.
In short, this isn’t just an integration—it’s a smarter, faster, and more scalable way to unlock the power of enriched data and take customer intelligence to the next level.
Why This Integration Delivers More Than Just Data
At the heart of this integration is a set of powerful features designed to simplify, optimize, and future-proof the way organizations manage enrichment.
- The integration takes a unified approach to data, bringing both B2B and B2C enrichment into a single solution. Businesses also gain the flexibility to run enrichment in potential match only mode, ensuring accuracy when exact matches aren’t available.
- The platform is highly configurable, with customizable transformations and properties that make it easy to adapt to unique business needs. Built with scalability in mind, it incorporates RIH task optimization and Workato-approved best practice recipes to deliver performance and reliability, even under demanding workloads.
- Maintaining trust in data is just as important as enriching it, which is why the solution includes recertification capabilities to continuously validate accuracy over time. To support transparency and control, teams can access detailed logs, real-time statistics, and proactive email notifications, keeping them fully informed at every step.
Together, these features create a foundation that not only enriches data but also makes it more trustworthy, actionable, and aligned with business goals.
Key Technologies Powering the Reltio-ZoomInfo Integration
Reltio MDM: Connected Data Platform
Reltio is a cutting-edge Master Data Management (MDM) solution that enables an MDM solution with an API-first approach. It offers top-tier MDM capabilities, including Identity Resolution, Data Quality, Dynamic Survivorship for contextual profiles, and a Universal ID for all operational applications. It also features robust hierarchy management, comprehensive Enterprise Data Management, and a Connected Graph to manage relationships. Additionally, Reltio provides Progressive Stitching to enhance profiles over time, along with extensive Data Governance capabilities.
Reltio Integration Hub: No-Code, Low-Code Integration Platform
Reltio offers a low-code/no-code integration solution, Reltio Integration Hub (RIH). RIH is a component of the Reltio Connected Customer 360 platform, which is an enterprise MDM and Customer Data Platform (CDP) solution. RIH provides the capabilities to integrate and synchronize data between Reltio and other enterprise systems, applications, and data sources.
ZoomInfo
ZoomInfo is a leading go-to-market intelligence platform that empowers businesses with accurate, real-time data on companies and professionals. By combining firmographic, demographic, and behavioral insights with advanced analytics, ZoomInfo helps organizations identify the right prospects, enrich customer records, and accelerate revenue growth. Its trusted datasets and automation capabilities make it a go-to solution for driving smarter marketing, sales, and data management strategies.
Join the Data Revolution
Ready to take your data strategy to the next level? Discover the full potential of the new ZoomInfo Integration for Reltio MDM, designed and developed by Fresh Gravity. Contact us for a personalized demo or to learn how this revolutionary tool can be a game-changer for your business.
For a demo of this pre-built integration, please write to info@freshgravity.com
Active Metadata: Powering the Next Generation of Data Intelligence
September 9th, 2025 WRITTEN BY FGadmin Tags: active metadata, Automation, data discovery, data governance

Written by Neha Sharma, Sr. Manager, Data Management
In the evolving world of data management, metadata is no longer just about documentation — it’s about activation. While traditional metadata systems have served as essential catalogs, they often sit idle, underutilized, and disconnected from the daily flow of data operations.
This is where Active Metadata changes the game.
What Is Active Metadata?
Active metadata refers to metadata that is continuously updated, automatically enriched, and directly integrated into data workflows and tools. Instead of sitting passively in a catalog, active metadata drives context, action, and automation across your data ecosystem.
Passive vs. Active Metadata
| Passive Metadata | Active Metadata | |
| Source | Manually added or imported | Dynamically harvested & updated |
| Usage | Stored in catalogs | Embedded in workflows & UIs |
| State | Static, descriptive | Real-time, behavioural, contextual |
| Value | Reference documentation | Decision-making and automation driver |
Why Active Metadata Matters
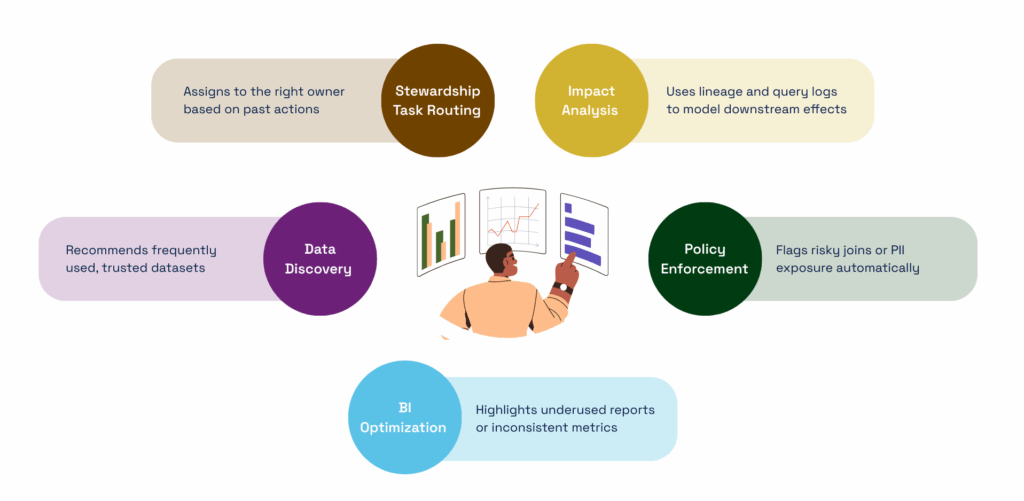
- Faster Data Discovery
Behavioral metadata (e.g., who queries what, how often) helps recommend the most relevant datasets and dashboards. - Smarter Governance
Data classification, lineage, and usage insights empower Data Governance teams to dynamically enforce policies in real-time by automating controls, tracing impact, and prioritizing actions based on data value and risk. - Informed Stewardship
Stewards can identify where definitions are missing, what’s out of compliance, and where users are struggling. - Accelerated Issue Resolution
Metadata-aware systems can route requests to the right owners, flag broken pipelines, or highlight high-impact changes — automatically.
Key Components of Active Metadata
A mature Active Metadata implementation typically includes:
Continuous Harvesting
- From data warehouses, BI tools, data quality platforms, APIs, pipelines, etc.
- Captures technical, operational, and behavioural metadata in near-real time
Unified Metadata Graph
- Combines lineage, glossary, classification, policies, usage, and ownership
- Links business context to technical assets
Embedded Metadata Experiences
- Surfaces metadata inside your tools: SQL editors, notebooks, dashboards, ticketing systems
- Enhances context right where work happens
Intelligent Recommendations
- Auto-suggests stewards, definitions, classifications, or escalation paths based on usage patterns
- Supports data enablement and compliance automation
Real-world Use Cases
 Is This Just a Catalog Feature?
Is This Just a Catalog Feature?
No. While many active metadata systems integrate with catalogs, they go beyond them. A robust Active Metadata approach typically includes:
- Metadata orchestration platforms
- Data observability and pipeline monitoring tools
- Stewardship and workflow automation systems
- BI metadata connectors and access control bridges
You don’t have to buy a tool to get started. Most enterprises already have metadata flowing — it’s about activating it intelligently.
What to Look for in an Active Metadata Platform
When evaluating tools or building your own solution, prioritize platforms that:
- Continuously sync metadata from across your stack
- Offer flexible APIs and push/pull integrations
- Provide behavioral insights (not just schema or tags)
- Enable human-in-the-loop workflows (approvals, reviews)
- Are extensible — you’ll never stop adding tools or use cases
What’s Next? Toward Autonomous Metadata Operations
As organizations mature, active metadata lays the groundwork for autonomous data ecosystems:
- Stewards get AI-assistants recommending the next best actions
- Pipelines self-adjust based on usage and lineage
- Access controls adapt dynamically based on risk and sensitivity
- Compliance becomes continuous and explainable
This isn’t a vision for 5 years from now. It’s starting now—in the most data-forward enterprises.
How Fresh Gravity Can Help
At Fresh Gravity, we specialize in helping enterprises:
- Assess current metadata maturity across tools and platforms
- Design and implement unified, active metadata strategies
- Integrate with your existing catalogs, governance tools, and cloud platforms
- Build intelligent workflows that bring metadata to life
Whether you’re starting with a data catalog, building lineage maps, or planning AI-driven stewardship — we help you activate your metadata and accelerate your data value.
Ready to Move from Metadata to Intelligence?
To discuss how Active Metadata can power discovery, governance, and innovation across your enterprise, write to us at info@freshgravity.com.
Measuring CDO Impact Beyond ROI
June 30th, 2025 WRITTEN BY FGadmin Tags: data governance, data quality, ethical data use, process automation, structured data

Written by Monalisa Thakur, Sr. Manager, Client Success
The Million Dollar Mistake That Never Happened
In 2022, a major U.S. financial institution found itself under federal investigation following concerns that its mortgage approval algorithms were unintentionally discriminating against an important segment of the population. Internal data showed that Black and Latino borrowers were disproportionately denied refinancing, despite qualifying under federal relief programs during the pandemic.
This early action helped the company course-correct. It paused the flawed model’s rollout, revised its decision logic, and introduced bias checks and review frameworks. While other banks were grappling with regulatory fines and public backlash, this institution quietly sidestepped disaster.
There was no headline saying, ‘million dollars saved’. But reputational damage was avoided. Legal costs were minimized. And most importantly, trust — arguably the institution’s most valuable asset — was preserved.
This was a data governance failure and a data governance success. Governance processes failed to surface potential fairness issues in how the algorithm was applied and evaluated. There were no clear audit mechanisms or stakeholder review gates in place. It took executive vigilance to fill the gap. Had ethical oversight and bias checks been embedded earlier, the issue might never have progressed so far.
This is exactly why the Chief Data Officer (CDO) role matters—even when it’s unofficial. In this case, it was a senior data leader, not yet titled CDO, who caught the flaw. While data governance has traditionally focused on data quality, consistency, and policy enforcement, its scope is expanding. Today’s CDOs are increasingly expected to steward not just structured data, but also the fairness, transparency, and accountability of data used in AI and algorithmic models. Flagging risks early and embedding ethical guardrails is becoming a part of the modern CDO’s responsibility. Sometimes, the most important data wins are the scandals that never make the news.
The ROI Obsession: Why We Need a New Metric for CDO Success
Organizations love numbers. It’s why traditional CDO performance metrics revolve around tangible outcomes:
- Revenue growth from data-driven initiatives
- Cost savings through process automation
- Increased data quality and governance efficiency
These are important things. But they don’t tell the full story. The real power of data leadership isn’t just in making money—it’s in shaping a culture that leverages data responsibly, ethically, and innovatively.
Yet, CDOs like the one in our story often find themselves fighting for recognition because their success is measured only in visible returns. The invisible value—employee morale, trust in data, risk mitigation, and innovation culture is harder to quantify. The challenge is not that these outcomes are ignored, but that they often lack consistent ways to measure or attribute.
The CDO Scorecard: Measuring What Matters
Behind every responsible data decision is a CDO—or someone playing that role—trying to make the invisible visible. Let’s reframe success. A truly impactful CDO Impact Scorecard should reflect not just business gains, but cultural shifts and ethical strength.
-
Trust in Data
Scenario: Imagine a global retailer where frontline employees rely on intuition, leading to inconsistent decisions. The CDO initiates a data literacy program, helping teams understand and trust insights. A year later, 80% of managers make data-driven decisions confidently.
Metrics: Increase in data usage, as captured via employee surveys, tool adoption rates, and training completion metrics, implies greater trust in data.
-
Room to Innovate
Scenario: At a healthcare startup, the CDO champions data sandboxes—secure environments where teams can test AI models without risk. Within six months, a junior analyst discovers a predictive trend that improves patient outcomes, sparking new product ideas.
Metric: Number of successful pilot projects or innovative use cases emerging from data teams.
-
Ethical Leadership
Scenario: A social media giant faces scrutiny over its data practices. Its CDO proactively establishes a transparency framework, making privacy policies clear and engaging external ethics boards. Public perception shifts from skepticism to trust.
Metric: Brand sentiment analysis linked to data privacy and ethics.
-
Risk Mitigation
Scenario: An airline CDO identifies inconsistencies in maintenance data that could lead to safety risks. Fixing them prevents a potential regulatory violation, avoiding millions in fines and reputational loss.
Metric: Number of risks mitigated before escalation.
-
AI Accountability & Fairness
Scenario: Imagine a retailer rolling out an AI-powered recommendation engine. Early results looked promising until a CDO-led review revealed the training data lacked representation from focused customer groups, leading to biased outcomes. The CDO introduced governance checks for all AI models, including fairness audits and documentation standards. The model was retrained, trust improved, and a company-wide responsible AI framework was established.
Metric: Number of AI models governed through fairness reviews; frequency of training data audits for bias.
Real Stories, Real Impact.
CDOs shouldn’t constantly prove their value in revenue figures alone. They champion fairness, build resilience, and create a culture where data helps people do the right thing.
That data executive in the story at the beginning of this blog wasn’t just a technical guardian—she was a protector of trust, a promoter of fairness, and a culture-builder. And that’s what impactful data leaders do.
While the previous story was inspired by real events, the following documented cases show how CDOs—or those in equivalent roles—create meaningful, lasting impact:
- Preston Werntz (Chief Data Officer, CISA) emphasized the importance of addressing bias in AI datasets, ensuring models are fair and trustworthy, and preventing reputational damage before it occurs.
- The U.S. Department of Education launched a data literacy initiative, empowering employees to make informed, data-driven decisions, showcasing the long-term benefits of investing in data culture.
- Richard Charles (CIO, Denver Public Schools) tackled bias in AI systems by implementing rigorous oversight, ensuring ethical data use that fosters trust and transparency.
- The Chief Data Officer Council developed a Data Ethics Framework for federal agencies, proactively mitigating risks and ensuring responsible data practices, demonstrating the importance of CDOs in crisis prevention.
Many organizations still don’t have CDOs. CIOs, CFOs, even COOs play this role quietly—but meaningfully. The title doesn’t matter as much as the mindset.
Where Fresh Gravity Fits In
At Fresh Gravity, we understand that the success of a data leader goes far beyond dashboards and KPIs. While we don’t supply CDOs directly, we help lay the foundation for them to thrive.
We work with organizations to:
- Design and establish the Data Office or CDO function, with clear mandates, roles, and governance models.
- Define and track qualitative KPIs that reflect data trust, innovation readiness, and literacy
- Help set up DG operating models to ensure the CDO has cross-functional influence and visibility.
- Help leaders (CDOs or otherwise) track the value of data programs—even when it’s not immediately financial
Whether your data leadership lies with a CDO, CIO, or an evolving role, we bring the experience, empathy, and tools to make your data vision sustainable.
Want to explore how intangible data value can be measured in your organization? Or how to demonstrate data governance impact through smart KPIs? Reach out to us—we’d love to share ideas, templates, and frameworks to get you started.
The Real Takeaway
Executives must embrace a broader view of data leadership. Boards and CEOs should:
✔️ Align CDO KPIs with long-term strategic goals, not just immediate returns
✔️ Recognize that intangibles create competitive advantage
✔️ Start tracking and rewarding cultural and ethical impact
Because in the end, the most valuable things a CDO brings to the table—trust, resilience, and innovation—are often the hardest to measure, but the most important to the governance of data.
Getting Started with Agentic Architecture
June 24th, 2025 WRITTEN BY FGadmin Tags: agentic AI, artificial intelligence, autonomous agents, large language model, modern AI, multi-agent architecture

Written By Soumen Chakraborty, Vice President, Artificial Intelligence
As large language models (LLMs) like GPT-4.x, Claude, and Gemini continue to evolve, the question shifts from “What can the model do?” to “How can we make it work as part of a system?” That’s where agentic architecture comes in — a design pattern that enables multiple intelligent agents to plan, reason, and act toward a goal, often using shared tools, memory, and context.
This is the 1st part of a blog series that will demystify agentic architecture, break down its core components, and set the foundation for building real-world applications using this powerful design. In this blog, we will cover the following topics under agentic AI: concepts, stages, and how to build it.
What Is Agentic Architecture?
Agentic architecture refers to a system design in which autonomous agents, powered by LLMs or other models, operate in coordination to solve complex tasks. Each agent is given:
- A role (e.g., researcher, summarizer, executor)
- A goal (defined by a user or system)
- Access to tools (e.g., search APIs, vector stores, databases)
- Memory and context (either persistent or task-specific)
Rather than a single monolithic LLM response, agentic systems operate more like a distributed AI workforce.
What are the Key Components of Agentic Architecture?
- Agents
Intelligent, task-driven entities that can reason, act, and communicate. Examples:- A document parser or extractor agent
- A data normalizer or standardizer agent
- A data quality validator agent
- A SQL or SPARQL query generator agent
- A summarizer or insight generator agent
- Model Context Protocol (MCP) Server (Control Plane)
Orchestrates agent workflows, manages state, routes tasks, and handles memory/context. - Memory Store
Shared memory or knowledge base (e.g., vector DB, Redis) that agents can read/write to. - Tool/Function Registry
A curated list of tools agents can use, such as APIs, databases, and external plugins. - Task Queue & Execution Engine
A flow engine that sequences agent calls and handles dependencies, retries, and fallbacks.
Why Agentic Architecture?
|
Traditional LLMs |
Agentic AI Systems |
|
One-shot response |
Multi-step reasoning & execution |
|
No memory |
Persistent, shared context |
|
Hard to scale |
Composable, modular agents |
| Black box |
Transparent workflows with logs |
Agentic design brings structure, modularity, and goal orientation to LLM-based workflows.
Analogy: The AI Startup Team
Imagine building a startup:
- The CEO agent sets the strategy (goal decomposition)
- The Research agent gathers information
- The Engineer agent builds features
- The QA agent tests the output
Each agent has a specific role but works toward a common goal, all of which are coordinated by a central platform, the MCP.
Example Use Case: Life Sciences Document Copilot
- User Input: “Summarize all supply chain issues related to active trials.”
- Agents Involved:
- Entity extractor
- KG query generator
- Summarizer
- Validator
- Outcome: A multi-agent pipeline retrieves, processes, and delivers a rich, context-aware answer.
How RAG, Tools, and Agents Work Together in Modern AI Systems
In agentic architectures, you’ll often hear about RAG (Retrieval-Augmented Generation), Tools, and Agents. While these may sound technical, each plays a unique role, and together, they power intelligent, context-aware, action-driven systems.
- RAG brings in the right context by grounding the AI in relevant, up-to-date information.
- Tools provide real-world capabilities, enabling the AI to take actions beyond just generating text.
- Agents are the orchestrators—they plan, reason, and act to achieve predefined goals by leveraging both RAG and tools.
In essence, RAG supplies the knowledge, tools enable the actions, and agents drive the intelligence that ties it all together.
Sample Workflow:
A Data Steward Agent receives a task to verify customer data inconsistencies.
- RAG: The agent uses RAG to retrieve past resolutions or policies from enterprise documents.
- Tools: It then calls a data validation tool or executes a transformation via an API.
- Agent Logic: Based on the outcome, the agent decides whether to escalate, auto-resolve, or ask for SME input.
Approach to build an AI Agent – Phase by Phase
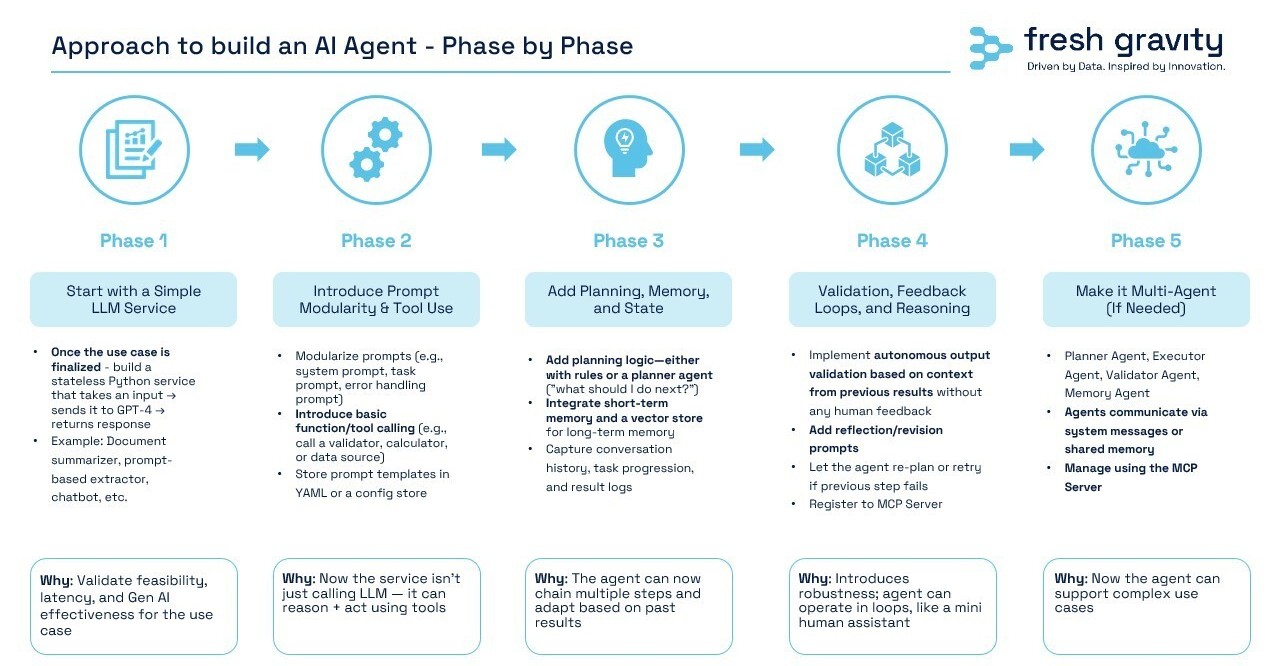
This 5-phase framework outlines a structured path to evolve from simple LLM-based solutions to intelligent, multi-agent systems capable of autonomous task execution.
- Phase 1 – Basic LLM Service:
Start with a stateless GPT-based service to validate feasibility and GenAI performance. - Phase 2 – Prompt Modularity & Tool Use:
Modularize prompts and integrate external tools to enable reasoning beyond text. - Phase 3 – Add Planning, Memory & State:
Introduce planning logic, memory (short-term & vector), and task tracking for adaptive, multi-step workflows. - Phase 4 – Feedback Loops & Validation:
Implement autonomous validation and revision via feedback (automated + human-in-the-loop). - Phase 5 – Multi-Agent Architecture:
Deploy specialized agents (Planner, Executor, Validator) that collaborate through a shared orchestration layer.
What’s Next?
Agentic architecture isn’t just a research concept — it’s a powerful blueprint for building intelligent, explainable, and collaborative AI systems.
As a next step, you should know how the brain of this architecture works. In the upcoming blogs, we will explore how to build an MCP server using FastAPI, register agents, and run your first multi-agent flow. Stay tuned.
Fresh Gravity’s AI capability is fueled by our top-tier AI engineering team is ready to support your journey in building intelligent agents. Feel free to reach out if you’d like to explore these topics further or see a live demo in action.
Driving Data Governance Success in Real Estate
June 4th, 2025 WRITTEN BY FGadmin Tags: alation, best practices, data governance, fragmented data governance, metadata management, strong data governance foundation

Written By Neha Sharma, Sr. Manager, Data Management
In today’s data-driven world, a strong data governance foundation is no longer optional — it’s essential. One U.S.-based real estate investment company and shared communications infrastructure provider embarked on a journey to modernize and streamline its data governance practices. The result was a major transformation that continues to deliver value across the organization.
The Challenge: Fragmented Data Governance
Like many organizations, this company faced significant challenges in managing and governing its sales data effectively. Key issues included:
- No structured governance operating model to define stewardship activities
- Lack of standardized policies, governance metrics, and data & analytics (D&A) standards
- No clear process for managing data dictionaries and metadata
- Limited transparency and accessibility of key data assets
- No dashboard or mechanism to track governance initiatives and measure success
Without a structured governance framework, ensuring data consistency, compliance, and usability across business units was a major hurdle.
The Approach: Building a Strong Governance Foundation
To support their enterprise-wide digital transformation, the focus was on strengthening Customer Relationship Management (CRM) operations through the implementation of a robust governance and metadata management framework. The following steps were taken:
- Established a governance operating model to promote domain-specific ownership and accountability, underpinned by clear policies and standardized procedures
- Built a Power BI dashboard to monitor governance adoption, measure effectiveness, and improve data literacy
- Developed a business glossary and data catalog using Alation, enabling data asset certification, dictionary curation, and policy documentation
- Automated metadata management using Alation’s catalog APIs, REST interfaces, and custom automation templates
The Result: A Complete Transformation
The results demonstrated the impact of having the right governance tools and processes in place:
- Clear ownership and accountability – Governance roles and responsibilities were formalized and adopted
- Increased visibility and training – Teams were better equipped to use Alation and follow governance best practices
- Efficient KPI and policy maintenance – Governance insights became readily available to end-users
- Enhanced data lineage tracking – Business glossary provided transparency into data relationships
- Eliminated communication gaps – Standardized nomenclature resolved field name confusion
- Centralized metadata management – Organizational knowledge was captured and made accessible
- Consolidated governance dashboard – A single source of truth supported better decision-making and tracking
This transformation highlights how a well-structured governance framework, supported by tools like Alation, can significantly improve data quality, operational efficiency, and alignment with strategic business objectives.
Looking Ahead: Enabling Scalable Governance with Alation
Organizations seeking to modernize their data governance capabilities can take inspiration from this journey. With the right strategy, technology, and execution, it’s possible to create a sustainable governance model that delivers real business impact.
Partnering with experts who understand how to implement and scale platforms like Alation can accelerate your governance initiatives. Whether you’re just getting started or ready to advance your current framework, strong implementation guidance, automation, and user enablement are key to long-term success.
A 10-Minute Guide to the Evolution of NLP
May 5th, 2025 WRITTEN BY FGadmin Tags: AI, GenAI, machine learning, natural language processing, NLP, structured data, use cases

Written by Sudarsana Roy Choudhury, Managing Director, Data Management
What is NLP?
Natural Language Processing (NLP) is a subfield of artificial intelligence and machine learning that focuses on the interaction between computers and human (natural) languages. It involves a range of computational techniques for the automated analysis, understanding, and generation of natural language data. Organizations across domains such as finance, healthcare, e-commerce, and customer service increasingly rely on NLP to extract insights from large volumes of unstructured data—such as textual documents, social media streams, and voice transcripts.
Key NLP tasks include tokenization, part-of-speech tagging, named entity recognition, syntactic parsing, sentiment analysis, and text classification. Advanced models, such as transformers (e.g., BERT, GPT), enable contextual understanding and generation of human-like responses. Real-time processing pipelines often integrate NLP models with stream processing frameworks to support use cases like chatbots, virtual assistants, fraud detection, and automated document processing. The ability to interpret, analyze, and respond to natural language inputs in real time is now a critical capability in enterprise AI architectures.
The positive impact of NLP has already started to be evident across the industry. NLP technologies have many uses today, from search engines and voice-activated assistants to advanced content analysis and sentiment understanding. The use cases vary by industry. Some of the very prominent use cases are
- Healthcare – e.g. Precision Medicine, Adverse Drug Reaction (ADR), Clinical Documentation, Patient Care and Monitoring
- Retail – e.g. Product Search and Smart Product Recommendations, Sentiment Analysis, Competitive Analysis
- Manufacturing – e.g. Predictive Maintenance and Quality Control, Supply Chain Optimization with real-time language translation, Customer Feedback Analysis
- Financial Services – e.g., Automated Customer Service and Support, Fraud Detection, Risk Management, Sentiment Analysis and Customer Retention
- Education – e.g. Personalized Learning, Automated Grading and Assessment, Enhanced Student Engagement by using chatbots, Accurate Insights from Feedback
The Evolution
The origins of Natural Language Processing trace back to early efforts in machine translation, with initial experiments focused on translating Russian to English during the Cold War era. These early systems were largely rule-based and simplistic, aimed at converting text from one human language to another. This foundational work gradually evolved into efforts to translate human language into machine-readable formats—and vice versa—laying the groundwork for broader NLP applications.
NLP began to emerge as a distinct field of study in the 1950s, catalyzed by Alan Turing’s landmark 1950 paper, which introduced the Turing Test—a conceptual benchmark for machine intelligence based on the ability to engage in human-like dialogue.
In the 1960s and 1970s, NLP systems were primarily rule-based, relying on handcrafted grammar and linguistic rules for parsing and understanding language. The 1980s marked a significant paradigm shift with the advent of statistical NLP, driven by increasing computational power and the availability of large text corpora. These statistical approaches enabled systems to learn language patterns directly from data, leading to more scalable and adaptive models.
The 2000s and 2010s witnessed a revolution in NLP through the integration of machine learning techniques, particularly deep learning and neural networks. These advancements enabled more context-aware and nuanced language models capable of handling tasks like sentiment analysis, question answering, and machine translation with unprecedented accuracy. Technologies such as recurrent neural networks (RNNs), Long Short-Term Memory (LSTM) networks, and later transformer-based architectures (e.g., BERT, GPT) propelled the field into a new era of innovation.
Today, NLP continues to evolve rapidly, enabling applications in conversational AI, voice assistants, real-time translation, and automated document analysis—transforming the way humans interact with machines across industries.
NLP and the Rise of Generative AI
The recent surge in Generative AI (GenAI) has propelled NLP into an even more central role in enterprise innovation. At the heart of GenAI systems lie powerful language models—such as GPT, PaLM, Claude, and LLaMA—that are built on foundational NLP principles. These models not only understand and generate human-like text but also drive a new class of capabilities: intelligent summarization, content creation, code generation, multilingual Q&A, and zero-shot reasoning. NLP techniques underpin key components of prompt engineering, retrieval-augmented generation (RAG), and fine-tuning, which are essential to customizing GenAI for domain-specific use cases. Whether powering copilots for legal review, AI agents for customer support, or personalized healthcare guidance, the synergy between NLP and GenAI is redefining how businesses engage with unstructured data and augment human intelligence at scale.
Looking Forward – What to Expect
As Natural Language Processing (NLP) continues to evolve, several forward-looking research directions and practical challenges are coming into sharper focus. A key area for advancement lies in contextual understanding and common-sense reasoning—enabling models to go beyond surface-level semantics and grasp deeper meaning and intent within language. Enhancing this capability is critical for more accurate human-computer interactions.
Another emerging frontier is multimodal learning, where NLP systems are integrated with visual, auditory, and sensory data to facilitate richer and more human-like comprehension. This convergence enables machines to understand context not only from text but also from correlated signals across various modalities—paving the way for applications in robotics, autonomous systems, and next-generation AI assistants.
However, the journey toward such advancements is fraught with technical, ethical, and economic challenges. The development and deployment of large-scale language models require extensive computational resources, raising concerns about energy consumption and the associated environmental impact. Additionally, algorithmic bias, often rooted in skewed training data, poses serious threats to fairness and equity in AI-driven decisions.
Data privacy is another pressing issue, particularly in applications involving sensitive user information. Furthermore, the ethical implications of AI-powered text generation, manipulation, and decision-making demand clear governance, transparency, and accountability.
Overcoming these challenges necessitates global, interdisciplinary collaboration—combining expertise from machine learning, linguistics, ethics, law, and policy. International partnerships and open research ecosystems will play a pivotal role in shaping a responsible and sustainable future for NLP.
How Fresh Gravity Can Help
At Fresh Gravity, our team brings deep and diverse expertise in Artificial Intelligence, combined with a proven track record of delivering innovative and efficient solutions. We specialize in addressing complex NLP needs by helping organizations define the right strategy, architecture, and implementation roadmap. From model selection and customization to deployment and ongoing optimization, Fresh Gravity empowers businesses to unlock the full potential of NLP technologies—driving smarter insights, automation, and enhanced user experiences. Our NLP capabilities are also at the core of our GenAI solutions, helping clients build domain-aware copilots, fine-tune foundation models, and deploy scalable AI assistants.
For more information, please write to us at info@freshgravity.com.
Putting People First: Inside the Employee Experience at Fresh Gravity
April 16th, 2025 WRITTEN BY FGadmin Tags: Career conversations, Career development, Career manager connects, Employee engagement, Employee experience, Employee growth, Mentorship at work

Written by Sonali Kulkarni, Sr. Manager, People & Talent
We are part of a generation where a personalized action/process defines employee experiences. Post the great resignation, employee experience has gained huge momentum, and employees now expect an enhanced level of customization in their workplace interactions. To address this, organizations need to go beyond a one-size-fits-all approach. Fresh Gravity has understood and imbibed this approach since its initial years to create individualized experiences that boost engagement, productivity, and retention. As Fresh Gravity completes a decade, here are some key insights into how we’ve been crafting a tailored and meaningful employee experience:
- We ensure employees feel valued and that their needs, preferences, and career aspirations are acknowledged. Our bi-weekly or monthly career manager connects are designed to create meaningful touchpoints—where employees receive ongoing feedback, share upward feedback, and engage in mentorship conversations. These sessions provide personalized guidance across diverse topics, empowering individuals to align their goals and actively work toward their career aspirations.
- We offer tailored work environments, hybrid working options, a globally diverse workforce, and flexible schedules that enhance efficiency and job satisfaction, thereby leading to increased productivity.
- We focus on investing in individual growth, employee well-being, acknowledging and appreciating the effort,s and offering work-life balance. As a result, we have noticed higher retention rates.
- The firm has invested in a global learning management system that gives employees access to an array of courses that can be pursued with institutions and universities across the globe, making it easier for them to get certified and upskill. This has led to relevant and meaningful skill development, which helps with the growth of individual employees as well as helps the firm to get more business due to the updated talent pool.
- We invest largely in well-being and offer care for the employees and their family members. We have customized and added comprehensive insurance coverages to the benefit kitty, including medical insurance, OPD coverages, term life, and accidental plans. Beyond this, we provide 401K benefits, dental insurance, provident fund, ESIC, and other statutory benefits as applicable per geography.
- We follow compliance to the “T”. We always ensure data privacy and ethical use of employee data.
Enhanced employee experience is no longer a luxury but a necessity in today’s competitive talent landscape. Firms that prioritize customized employee experiences will benefit from a more engaged, productive, and loyal workforce while also achieving business success.
If you are looking to be a part of an organization where culture, care, and growth come together, please send us your resume at careers@freshgravity.com.
Data Security in the Age of Cyber Threats
April 14th, 2025 WRITTEN BY FGadmin Tags: Business cybersecurity, Cyberattacks, Cybersecurity threats, Data protection, Data security, Enterprise data security, Information security

Written by Marc A. Paolo, Managing Director, Client Success and HIPAA Privacy and Compliance Officer; and Sudarsana Roy Choudhury, Managing Director, Data Management
The term “data” refers to the collection of facts, statistics, and information used for analysis, reference, and decision-making. Data used and stored digitally is of a wide variety – personal, corporate, and retail are a few examples. Organizations use data in multiple ways to enable informed business decisions to align with their goals, objectives, and initiatives. Data is analyzed to be used in a wide variety of use cases – healthcare to improve patient treatment outcomes, retail to enable personalized sales, and hospitality to deliver personalized guest experiences, to name a few.
The Challenge
Data is being used widely, especially personal data, and as such, the need to protect against data vulnerability is stronger than ever. Unauthorized use of data is a reality, and hackers are continuously developing the tools to access data and use it to harm people and organizations. Sensitive data in the hands of such criminals can lead to major security incidents, known as data breaches. Data classification is a major step an organization can take to understand the risk and exposure based on the data it stores. Data in an organization can be classified into four major categories based on the sensitivity level:
- Public
- Internal
- Sensitive or Confidential
- Highly Confidential
Data exposed at each sensitivity level also carries with it a level of impact; sensitivity level combined with the anticipated impact helps an organization develop a risk assessment. A data risk assessment facilitates efficient data management, making it easier to manage and protect data, ensuring resources are allocated effectively.
Data classification positions an organization to manage data security risk. Some of the biggest data security risks can be categorized as follows:
- Accidental data exposure
- Insider threats
- Phishing attacks
- Malware
- Ransomware
- Cloud data storage breach
Each incident of a cyberattack and a subsequent loss of data can have some very dire implications for a person and/or organization. Your data, in the hands of the wrong people, can be used maliciously to cause personal harm. Identity theft, emotional trauma, and reputational damage are just a few examples. For organizations, the loss could be in terms of business downtime, data loss, monetary loss, reputation impact, and legal consequences. The impact can be long-lasting and may even threaten the survival of the organization.
How can data security be improved to minimize cyber threats?
Organizations must ensure data security so that cyberattacks can be prevented and intercepted before they cause any harm. This is not only a technical solution. Enterprise data security measures fall into three categories: administrative, physical, and technical. A well-rounded information security program includes safeguards in all three categories, and such measures help address the prevention of cybercrimes. There are standards which indicate which measures should be in place to have what is considered a “strong” program; these include ISO/IEC 27001, NIST, SOC2, and HIPAA, among many others.
- Administrative Measures include policies, procedures, and practices designed to manage and protect information systems. This includes training of employees on cybersecurity best practices to improve the strength of the “human firewall.” There are cyberthreats, such as phishing and social engineering, that a technical firewall cannot easily prevent, but knowledge about how to avoid falling prey to a phishing scheme can protect against such dangers.
- Physical Measures include measures to protect data in electronic systems, equipment, and facilities from threats, environmental hazards, and unauthorized intrusion. A few common physical measures include physical locks and barriers, security guards, surveillance cameras, lockable cabinets and safes, fences, and lighting.
- Technical Measures are the most obvious security safeguards that protect systems and data from unauthorized access, attacks, and other cyberthreats. Most people, when they think of data security, may think of “technical measures” first. These include encryption, access controls, data backup and disaster recovery, data loss prevention (DLP), and antivirus/anti-malware, to name just a few.
How Fresh Gravity Ensures Data Security
Fresh Gravity drives digital success for our clients by enabling them to adopt transformative technologies that make them nimble, adaptive, and responsive to the changing needs of their businesses. We enable our clients to achieve informed data-driven business outcomes by implementing Data Management, Analytics & ML, and Artificial Intelligence solutions. For all our solutions, we ensure that we adhere to the best practices of data security. We comply with the data security compliance requirements of our clients when implementing solutions for them. We also handle a lot of our clients’ data during analysis and implementation, so within Fresh Gravity, we have ensured that all the measures are strictly followed to ensure that the data is safe. Our team members’ data is also treated with the same level of security as our clients’ data. Fresh Gravity follows ISO27001 standards, and we have achieved a Silver certification by Cybervadis. We thus have a holistic Information Security Program in place to ensure maximum security and protection against cyber threats.
Navigating the Next Frontier: An Enterprise Information Architect’s Ongoing Journey in Life Sciences
April 2nd, 2025 WRITTEN BY FGadmin

Written by Colin Wood, Strategy & Solutions Leader, Life Sciences
Many of you may have read the LinkedIn posting announcing my new role at Fresh Gravity. I’m sure that more than a few readers are interested to learn why I accepted this role less than 6 months after announcing my retirement from AstraZeneca. I’ll use this article to share a snippet of my journey since retiring and what I hope to achieve in this new and exciting role.
Firstly, after retirement, I travelled to Las Vegas, Hawaii, and New Zealand with my wife. This was a wonderful trip, but of course all good things come to an end, and I found myself in a cold, grey UK in the middle of December with wet and muddy footpaths that made it challenging to enjoy the countryside walks.
Looking for something interesting to research, I scanned LinkedIn and technical resources. I became fascinated with the rapid pace of change relating to Large Language Models and was convinced that these introduced a truly significant change in Information Technology and perhaps society. Three things intrigued me at the time:
- What is the underlying mathematics underpinning LLMs?
- Why do LLMs hallucinate?
- Can LLMs, Knowledge Graphs, and Ontologies, supported by a strong backbone of master and reference data, be leveraged to improve the capabilities of an LLM?
I found some excellent Google courses introducing LLMs and Transformers, but I wanted to understand more about the foundations. Lacking a formal background in Machine Learning and with plenty of time on my hands, I decided to invest some time in understanding the foundations.
I found a wealth of recommendations for free learning materials on LinkedIn and progressed my learning of the foundations using the following resources.
- Linear Algebra (3Blue1Brown) – I have studied Linear Algebra before (>40 years ago), but the visualisations really bring the subject to life.
- Multivariate Calculus (Khan Academy) – Again, this is a topic I’ve studied and enjoyed before. Loved the material, though it was a bit stressful doing tests on this topic for the first time in 40 years. A key tip is that you need to practice calculus to avoid silly mistakes with minus signs.
- Statistics and Probability (StatQuest with Josh Starmer) – Another brilliant resource that also delves into Machine Learning and Large Language Models. I give it a triple BAM!
- Stanford Introduction to Machine Learning with Andrew Ng – I found this tremendously valuable as it emphasized the maths and statistics foundations of ML. Absolute highlight for me was solving the normal equation (X = (ATA)-1ATb) by hand. I’d never do it again (2 pages of matrix calculations are not to be taken lightly), but I learned a great deal!
I skimmed several other resources related to Deep Learning and Transformers, but at that point my attention was drawn to some fascinating papers by Juan Sequeda and others, including Knowledge Graphs as a source of trust for LLM-powered enterprise question answering. This and similar papers have now become a new area for my research.
What did I learn from all this?
- Clearly, I need continued intellectual input as I move into my later years.
- The capabilities of LLMs are absolutely astounding, but it’s not genuine intelligence; just applied mathematics and statistics. (In my view the capabilities are more to do with Linguistics and the remarkable properties of human language. Hallucinations are nothing unexpected, it’s just showing the limits of these techniques.)
- My gut feeling about LLMs, Knowledge Graphs, and Ontologies supported with assured master and reference data seems to be true.
The latter brings me to the conclusion that the future of Enterprise Information Architecture with Life Sciences companies lies in seamlessly connecting assured master and reference data with ontologies and knowledge graphs, while leveraging them effectively in LLMs.
Why Fresh Gravity?
I have worked with Fresh Gravity and with Ajit Kumbhare in the past and have always found them to be innovative, focused and successful at implementing and integrating the range of technologies and capabilities that interest me. They also have a strong presence in the Life Sciences industry, which is my primary area of expertise and interest.
Additionally, Fresh Gravity shares my view that the future for the Life Sciences industry should be to combine assured master and reference data, knowledge graphs, ontologies and Large Language Models (LLMs) to support scientific and enterprise questions.
With that background, I jumped at Ajit’s offer to join Fresh Gravity as a Strategy and Solutions Leader for Life Sciences. Thank you for giving me this exciting new opportunity.
For those who are concerned about my wife, this opportunity comes with sufficient flexibility to allow us to continue travelling and enjoying long-distance walks (we start the Southwest Coastal path in early May).
The 3 areas I hope to develop in this new role are:
- Support Fresh Gravity’s clients by applying my 33 years of experience in the Life Science industry. I hope to achieve this by defining common patterns for strategic implementation and integration of assured master and reference data.
- Introduce new IT and data governance processes to support this vision of connected data. This may need new or upgraded tools and processes to support end-to-end use of data.
- Clearly define the role of an Enterprise Information Architect, a role that is poorly defined in most organisations, but in my opinion, is crucial for the future of the Life Sciences industry.
Stay tuned for more blogs diving into each of these topics.
The Role of Ethical Practices in Strengthening Client Trust
March 28th, 2025 WRITTEN BY FGadmin

By Monalisa Thakur, Sr. Manager, Client Success
The Currency of Trust
Imagine you walk into a coffee shop every morning, greeted by the same barista who knows your order by heart. One day, you realize they’ve been charging you a little extra without telling you. At first, you wonder if it was a mistake, but then it happens again. It’s not a huge amount, but now you’re questioning their honesty. Was this intentional? What else are they hiding if they can be dishonest about something small? The trust is broken. You might never go back.
Now, apply this to business, especially in the consulting and data management space. Trust is our most valuable currency. Lose it, and the relationship crumbles. But how do we earn trust and maintain it? The answer lies in ethical practices.
Ethics is Not Just a Policy—It’s a Practice
In consulting, clients come to us with problems, hoping for expertise and guidance. But behind every dataset, every decision, and every recommendation, there is a responsibility—one that extends beyond delivering results. Ethical practices are what separate short-term transactional relationships into longstanding partnerships.
The Power of Transparency
Years ago, I worked on a project where a key client stakeholder asked us to tweak reports to “look better” in front of senior leadership. The data wasn’t technically incorrect, but the way they wanted it presented would have masked underlying issues. It was a crossroads—do we do what was asked or do we stand by integrity?
We chose to be honest. We advised them that while we could refine the presentation, it was crucial to highlight real risks so leadership could make informed decisions. The stakeholder hesitated but ultimately appreciated the honesty. That moment cemented our credibility, and the relationship continued for years.
Contrast this with another situation I heard about—a consultant who went along with misleading data visualizations to keep a client happy. It worked in the short term, but when senior leadership uncovered the real issues later, the consultant’s credibility was ruined. The firm lost not just the client, but also its reputation in that industry.
Clients don’t always like what they hear, but they respect honesty. Transparency fosters trust, even when the truth is uncomfortable.
Data Privacy: More Than Compliance
With data at the core of modern business, handling it correctly isn’t just an ethical choice—it’s a legal necessity. Regulations like GDPR, CCPA, and industry-specific policies dictate how data should be collected, accessed, and used. Ethical intuition is valuable, but laws set the boundaries.
I once witnessed a consulting firm accidentally gain access to more client data than they should have. Instead of reporting it, they used the extra data to generate deeper insights. It seemed like a win—until the client found out.
Imagine you give your accountant access to your bank records for tax purposes, only to later find out they’ve used that access to analyze your spending habits and sell insights to marketers. The trust, is bound to be shattered and likely, laws broken as well, leading to legal consequences.
That’s exactly what happened with this consulting firm. The client felt violated, and the engagement ended abruptly. More than just trust being lost—laws were potentially broken, and the firm faced reputational and legal risks. The lesson? Just because you can use data doesn’t mean you should.
Handling data responsibly isn’t optional. Beyond compliance, it’s about respecting client ownership and maintaining credibility. When clients know their data is safe with you, they’ll keep coming back—not out of obligation, but because they trust you.
Setting Boundaries, Not Just Delivering
Ethical consulting isn’t about saying “yes” to everything. It’s about guiding clients toward the right decisions, even when it’s not what they want to hear.
A colleague once told me about a client who wanted to implement an AI-driven analytics tool without cleaning their messy, duplicate-ridden data. They insisted that technology would “fix” it. Instead of blindly executing, the consultant pushed back, explaining that bad data would only lead to misleading results. The client resisted but eventually agreed to a data governance overhaul first. The outcome? A successful AI implementation that worked as intended—and a client who saw us as strategic partners rather than just vendors.
Compare this to another case where a consultant, eager to please, moved forward with implementing an advanced analytics tool without addressing the data quality. The result? The AI model made poor predictions, and the client blamed the consultant for a “failed” project. That consultant was never called again.
Saying “no” when necessary is an ethical responsibility. Short-term gains should never override long-term integrity.
Walking the Talk: The Fresh Gravity Approach
At Fresh Gravity, we believe ethics in data management isn’t an abstract concept—it’s the foundation of everything we do. Our approach to data governance, compliance, and strategy ensures that clients don’t just get results, but results they can trust.
We assess, recommend, and implement solutions with one guiding principle: if it’s not ethical, it’s not sustainable. Whether it’s helping clients build governance frameworks, ensuring fair data usage, or advising on best practices, we prioritize trust over shortcuts.
But our commitment to ethics doesn’t stop there. We actively educate our clients on best practices, helping them establish frameworks that embed ethical decision-making into their everyday operations. We don’t just solve problems—we build cultures of integrity that sustain businesses for the long run.
For example, we recently worked with a client who struggled with internal data access policies. Employees had more access than necessary, violating a fundamental security principle known as the “minimum necessary” rule, where individuals should only access the data required for their job. In many such cases, such access can even breach regulatory requirements.
Instead of offering a quick compliance fix, we collaborated with them to design a robust, role-based access model that not only addressed security concerns but also ensured operational efficiency. The result? A sustainable governance framework that safeguarded sensitive information while maintaining productivity.
Moreover, we foster a culture where our consultants are empowered to challenge unethical requests. If a client asks for something that compromises integrity, we don’t just refuse—we educate them on why ethical data practices lead to better long-term outcomes. This advisory mindset has helped us build strong, trusted relationships with clients who value more than just technical expertise.
The Long Game of Ethics
At Fresh Gravity, ethics isn’t just a policy—it’s embedded in one or more of our core organizational values. Our foundation is built on passion, integrity, openness, respect, diligence, empowerment, and adaptability. Integrity, which includes honesty and ethical behavior, is at the heart of how we operate. We don’t take shortcuts or compromise on doing what’s right, even when it’s difficult. Our values shape the way we engage with clients, ensuring trust isn’t just earned, but consistently upheld.
We empower our consultants to challenge unethical requests and guide clients toward responsible, effective solutions. Our governance frameworks are built not just for compliance, but for long-term trust and sustainability.
For us, ethics isn’t just about doing the right thing—it’s what makes Fresh Gravity a trusted partner. Because in the end, the strongest client relationships aren’t built on transactions; they’re built on trust.
Turning Complexity into Clarity: Organizing Unstructured Data Effectively
March 25th, 2025 WRITTEN BY FGadmin

Written by Neha Sharma, Sr. Manager, Data Management
In this age of information, organizations are inundated with data from countless sources – social media, emails, customer feedback, IoT devices, and much more. While this abundance of data holds immense potential, much of it is unstructured, making it challenging to analyze and leverage for decision-making. Organizing unstructured data effectively is key to transforming complexity into clarity, unlocking insights that drive innovation and growth.
What is Unstructured Data?
Unstructured data refers to information that doesn’t follow a predefined structure or format. Unlike structured data, which is neatly organized in rows and columns, unstructured data can include text files, images, videos, audio recordings, and other formats that are less straightforward to process. Various estimates suggest that unstructured data makes up approximately 80% to 90% of all data generated today, with sources such as MIT Sloan and Forbes highlighting its rapid growth and critical role in enterprise data management. This underscores its significance in the modern digital landscape and the need for effective strategies to manage and analyze it.
The Challenges of Unstructured Data
Organizing unstructured data is no small feat due to its:
- Volume: The sheer amount of unstructured data can overwhelm traditional systems.
- Variety: Unstructured data exists in diverse formats, requiring different processing techniques.
- Velocity: The rapid generation of data demands real-time or near-real-time processing.
- Veracity: Ensuring the accuracy and reliability of unstructured data can be difficult, especially when dealing with noisy or incomplete information.
Strategies for Organizing Unstructured Data
To harness the power of unstructured data, organizations must implement robust strategies that make it accessible and actionable. Here are key steps to achieving this:
- Data Classification and Tagging: Start by categorizing your data based on its type, source, or relevance. Automated tools powered by machine learning can analyze data attributes and apply tags or metadata, making future retrieval and organization easier.
- Implement Natural Language Processing (NLP): For text-heavy unstructured data, NLP can extract meaning, detect sentiment, and identify patterns. From customer reviews to support tickets, NLP helps uncover actionable insights hidden in text.
- Leverage AI and Machine Learning: Advanced algorithms can identify relationships, trends, and anomalies within unstructured data. These technologies excel in processing images, videos, and even voice data, offering deeper analysis beyond human capabilities.
- Adopt Scalable Data Storage Solutions: Cloud-based storage systems designed for unstructured data, such as data lakes, provide the scalability needed to manage large volumes. These platforms support integration with analytics tools for streamlined processing.
- Data Governance and Security: Effective data organization requires robust governance policies to ensure data quality, consistency and cohesiveness, privacy, and compliance. Assigning ownership and implementing access controls protect sensitive information while maintaining clarity in data management.
Real-World Applications of Organized Unstructured Data
- Healthcare: Analyzing unstructured data from patient records, medical imaging, and clinical notes aids in disease diagnosis and personalized treatment.
- Retail: Insights from customer reviews, social media, and purchase history enable retailers to refine their offerings and enhance customer experiences.
- Finance: Fraud detection and risk assessment benefit from analyzing unstructured data, such as emails, transaction records, and voice calls.
- Entertainment: Media companies can benefit from organizing unstructured data like video, metadata and viewer preferences to recommend content and improve engagement.
The Road Ahead
Organizing unstructured data is an ongoing journey that requires technological innovation, strategic planning, and a commitment to continuous improvement. By embracing tools and techniques that simplify the complexity of unstructured data, organizations can transform overwhelming information into a strategic asset.
In a world driven by data, the ability to turn complexity into clarity is not just a competitive advantage – it’s a necessity. Whether it’s improving decision-making, enhancing customer experiences, or driving operational efficiency, organized unstructured data is the foundation for a smarter, more agile future. Reach out to us at info@freshgravity.com if you are ready to unlock the power of your data.
Streamlining Databricks Deployments with Databricks Asset Bundles (DABs) and GitLab CI/CD
March 21st, 2025 WRITTEN BY FGadmin

Written by Atharva Shrivas, Consultant, Data Management and Ashutosh Yesekar, Consultant, Data Management
As data engineering and analytics pipelines become more complex, organizations need efficient ways to manage deployments and enhance collaboration. Traditional approaches often involve redundant code, scattered dependencies, and inconsistent environments.
Databricks Asset Bundles (DABs) provide a structured, streamlined way to package, share, and deploy Databricks assets, simplifying collaboration across teams and environments. By integrating GitLab CI/CD, we can automate the entire development lifecycle, ensuring efficient version control, validation, and controlled deployments across multiple Databricks workspaces.
In this blog, we’ll explore how DABs can enhance data projects and streamline workflows, empowering organizations to navigate the complexities of modern data engineering effectively.
Who Can Leverage DABs?
DABs are particularly useful in scenarios where:
- Infrastructure as Code (IaC) is required for managing Databricks jobs, notebooks, and dependencies
- Complex code contribution and automation are essential to avoid redundancy
- Continuous Integration and Continuous Deployment (CI/CD) are a requirement for rapid, scalable, and governed workflows
Scenarios for DAB Implementations
Consider a scenario where multiple data engineers work on a pipeline following the Medallion architecture. This pipeline involves:
- Numerous metadata files
- Redundant code spread across multiple notebooks
- Challenges in maintaining and scaling workflows
By using DABs, developers can:
- Modularize workflows by creating generic notebooks that dynamically execute with different base parameters
- Eliminate redundant code, making pipelines more scalable and maintainable
- Collaborate efficiently by packaging all necessary assets into a single bundle that can be versioned and deployed easily
CI/CD Workflow for DABs with GitLab
The following diagram represents the Databricks CI/CD pipeline using GitLab as the repository and CI/CD tool, enabling a structured and approval-based deployment process: 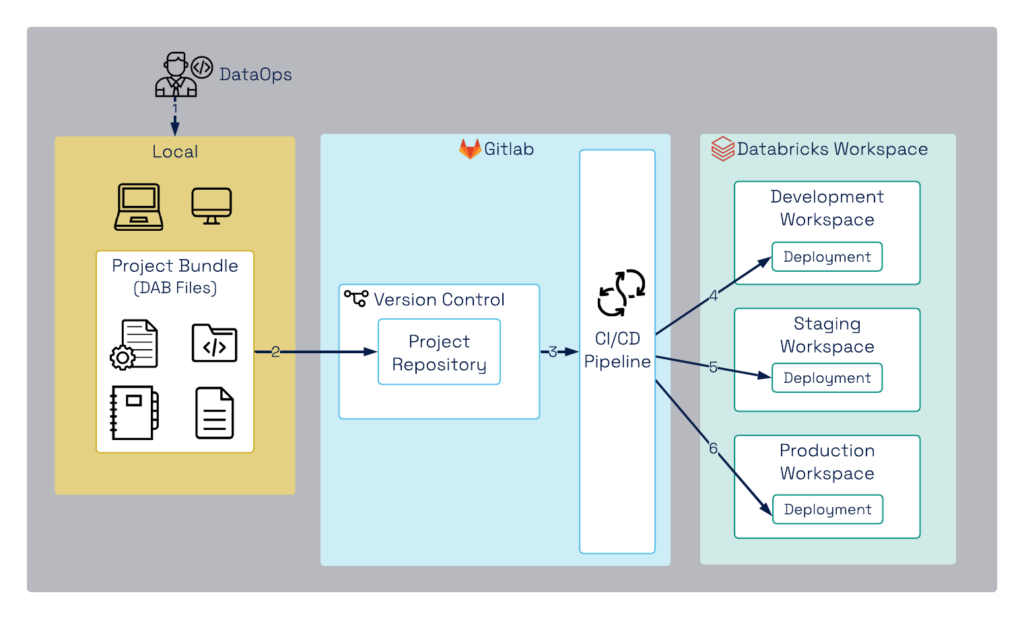
Figure 1. DAB deployment Workflow with GitLab CI/CD
- Development in Local Environment
- Developers create notebooks, job configurations, and dependencies in their local environment.
- These are packaged into a Databricks Asset Bundle (DAB), which includes:
- Notebooks
- Configurations
- Library dependencies
- Job definitions
- Version Control with GitLab Repository
- The DAB files are pushed to a GitLab repository to maintain:
- Version history for rollback and tracking
- Collaboration among teams
- Automation triggers for the CI/CD pipeline
- The DAB files are pushed to a GitLab repository to maintain:
- CI/CD Pipeline Execution with GitLab CI/CD
- Once the DAB files are committed, GitLab CI/CD triggers the pipeline, which automates:
- Code validation (linting, static analysis)
- Unit testing to verify notebook functionality
- Packaging and artifact creation
- Once the DAB files are committed, GitLab CI/CD triggers the pipeline, which automates:
- Deployment to Databricks Development Workspace
- Successfully validated DABs are deployed to the Development Workspace
- Developers test and refine their code before moving forward
- Deployment to Databricks Staging Workspace
- The CI/CD pipeline deploys the bundle to the Staging Workspace, where:
- Integration testing
- Performance testing
- User Acceptance Testing (UAT) takes place
- The CI/CD pipeline deploys the bundle to the Staging Workspace, where:
- Approval-Based Deployment to Production Workspace
- Final deployment to production requires explicit approval from:
- Management
- DataOps Leads
- Security & Compliance Teams
- Once approved, the Release Manager or an automated approval workflow in GitLab CI/CD triggers deployment to the Databricks Production Workspace. This ensures:
-
- Governance & compliance
- Risk mitigation
- Controlled and auditable releases
-
- Final deployment to production requires explicit approval from:
Advantages of Using Databricks Asset Bundles (DABs)
- Efficient Code Versioning and Collaboration
- Developers can systematically version control their code and collaborate seamlessly using GitLab repositories
- Declarative and Simple Deployment
- DABs use a simple YAML-based declarative format, allowing the deployment of multiple resources like jobs, pipelines, and Unity Catalog objects with minimal configuration
- Automated Software Development Lifecycle
- Enables organizations to apply agile methodologies and enforce a structured SDLC (Software Development Lifecycle) for Databricks projects
- Approval-Based Governance for Production Deployments
- Prevents unauthorized changes by enforcing a structured approval process before deploying to production
- Scalability & Maintainability
- Reduces code complexity by allowing reusable components and standardized configurations, making large-scale data pipelines easier to manage
In the ever-evolving world of data engineering, ensuring efficiency, scalability, and consistency across Databricks environments is essential for organizations aiming to stay competitive. By leveraging Databricks Asset Bundles (DABs) and integrating GitLab CI/CD, businesses can streamline their workflows, improve collaboration, and automate deployments, ultimately reducing operational overhead and accelerating time-to-market.
At Fresh Gravity, we understand the challenges companies face in modernizing their data infrastructure. Our team of experts is committed to helping organizations optimize their Databricks workflows through tailored solutions and industry best practices. From designing custom CI/CD pipelines to implementing governance controls and automating infrastructure provisioning, we provide end-to-end support to ensure your Databricks environment operates at its highest potential.
Reference:
1. https://docs.databricks.com/en/dev-tools/bundles/index.html
The Role of Data Governance in Driving Business Intelligence and Analytics
March 18th, 2025 WRITTEN BY FGadmin

Written by Monalisa Thakur, Sr. Manager, Client Success
A Tale of Two Analysts: The Power of Good Data
Meet Sarah and Jake. Both are data analysts at different companies, each tasked with providing insights to drive business decisions. Sarah spends her time confidently pulling reports, analyzing trends, and delivering reliable insights. Jake, on the other hand, is constantly questioning the data—he’s chasing down missing fields, struggling with inconsistent formats, and getting different answers for the same question depending on the system he pulls the data from.
Sarah’s company has a robust Data Governance (DG) framework in place. Jake’s? Not so much. While Jake is firefighting data issues, Sarah is providing valuable recommendations that her leadership team can trust.
But here’s the thing—Jake’s company isn’t a mess. They have great people, solid tools, and ambitious goals. They just don’t have the right guardrails to make data a true asset. That’s where Data Governance comes in.
Why Data Governance Matters for Business Intelligence & Analytics
Data Governance (DG) isn’t just about control—it’s about enabling better, faster, and more confident decision-making. Without it, Business Intelligence (BI) and analytics are built on a shaky ground. Here’s how DG directly enhances BI:
- Data Quality & Consistency: Ensuring data is clean, standardized, and trustworthy means analytics reports are accurate and meaningful. Without high-quality data, reports can be misleading, leading to incorrect business strategies. With governance, businesses can establish standardized definitions, formatting, and validation rules to maintain integrity across all data sources.
- Data Accessibility & Security: DG helps define who can access what data, striking the right balance between openness and protection. Organizations can ensure that sensitive information remains secure while still making valuable data available to those who need it, promoting efficiency and compliance.
- Data Lineage & Trust: When decision-makers ask, “Where did this number come from?” DG ensures there’s a clear, documented answer. Transparency in data lineage means that any anomalies can be quickly traced back to their source, reducing errors and instilling trust in analytics.
- Compliance & Risk Reduction: With increasing regulations like GDPR and CCPA, organizations can’t afford to overlook data governance. Regulatory requirements demand strict data management, and proper governance ensures that companies avoid hefty fines while maintaining a strong reputation.
- Efficiency & Productivity: Analysts spend less time cleaning and validating data and more time delivering actionable insights that drive business growth.
Fresh Gravity: Helping Companies Take Charge of Their Data
At Fresh Gravity, we specialize in making Data Governance practical, achievable, and impactful. We don’t believe in just handing over theoretical frameworks—we work alongside organizations to implement governance models that actually work for their business.
Our Approach to Data Governance
To ensure organizations achieve real, lasting success with their data governance initiatives, Fresh Gravity follows a structured, yet flexible approach as shown in the figure below. The structured methodology provides a robust framework for consistency, while the flexibility allows clients to customize and tailor the approach to their specific needs and goals.
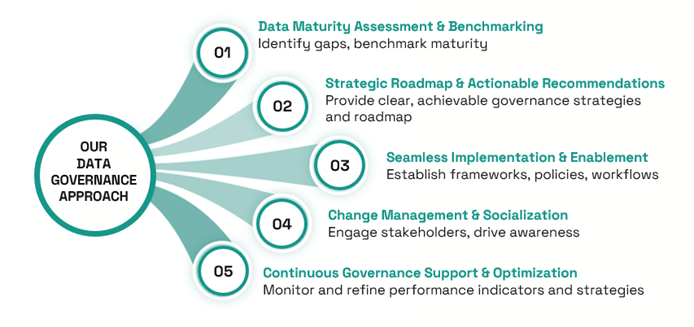
Figure 1. Our Data Governance Approach – A Snapshot
- 01 Data Maturity Assessment & Benchmarking: We evaluate your current data landscape, identify gaps, and benchmark against industry best practices to ensure your governance strategy is competitive and effective. Our assessment provides a clear understanding of where your organization stands and what steps are needed for improvement.
- 02 Strategic Roadmap & Actionable Recommendations: We provide practical, achievable governance strategies that align with business goals. Rather than overwhelming organizations with complex frameworks, we focus on actionable, high-impact changes that drive real improvements in data reliability and usability.
- 03 Seamless Implementation & Enablement: Fresh Gravity works closely with the client’s teams to establish governance frameworks, define policies, and integrate governance into everyday workflows. From selecting the right tools to embedding governance processes, we ensure a smooth and effective rollout.
- 04 Change Management & Socialization: Governance is only successful when people adopt it. We actively engage stakeholders, promote awareness, and integrate governance into company culture through structured communication, training, and advocacy efforts. We help teams see governance as an enabler, not a blocker.
- 05 Ongoing Governance Support & Optimization: Data governance is not a one-time project—it’s an evolving discipline. We provide continued support, monitoring, and training to ensure governance efforts stay effective as business needs change. Our goal is to embed governance as a sustainable and valuable practice.
Bringing It All Together
Back to our story—imagine if Jake’s company had a well-defined Data Governance strategy. Instead of spending hours validating reports, Jake could be delivering powerful, data-driven insights. Leadership wouldn’t have to second-guess reports, and decisions could be made faster and with confidence.
That’s the power of Data Governance in Business Intelligence and Analytics—not just fixing problems but unlocking true business value from data.
The organizations that succeed today and will continue to do so in the future are the ones that turn their data into a strategic asset rather than a liability. At Fresh Gravity, we help businesses take control of their data—ensuring it’s trusted, secure, and actionable.
If your organization is ready to move from data chaos to data confidence, Fresh Gravity is here to help. Let’s work together to build a Data Governance Model that fuels smarter decisions, drives competitive advantage, and secures long-term success. Reach out to us at info@freshgravity.com and start your DG journey today.
Empower, Inspire, Act: Key Insights from Our IWD Session
March 12th, 2025 WRITTEN BY FGadmin Tags: Diversity, Inclusion, international women's day

Written by Prerna Khanna, Associate, Marketing
This International Women’s Day, Fresh Gravity hosted a session with two power-packed women – Vahbiz Bharucha, Former Captain of the Indian Women’s Rugby Team, and Aishwarya Phadke, Founder of Travel Dirty. The session was moderated by Preeti Desai, Senior Manager, Client Success, Fresh Gravity who facilitated the discussion with insightful questions.
This year’s theme, #AccelerateAction, resonated throughout the discussion as our speakers shared their journeys, challenges, and triumphs. Their stories were not just inspiring but also packed with practical lessons on resilience, self-growth, and taking charge of our lives.
This session was even more inspiring because both speakers have taken unconventional paths to success.
For Aishwarya, the journey into the travel industry was not a straight road. She explored multiple avenues before realizing that travel along with its business aspect was her true calling. Today, she is building more than just a travel company – she is fostering a quiet community with the philosophy of “alone but together”.
For Vahbiz, sports has always been more than just a hobby – it has been a source of motivation and self-improvement. From a young age, she was drawn to the competitive spirit and personal growth that sports offered, constantly pushing herself to be better than she was the day before. Vahbiz is also a physiotherapist. She mentioned that since childhood she wanted to serve the community and that’s how physiotherapy became the perfect bridge between her love for sports and her desire to help people.
Their paths may be different, yet each puts out valuable life lessons. Vahbiz’s journey highlights how passion, discipline, and persistence can shape both personal and professional success, while Aishwarya’s path focuses on the importance of exploring, adapting, and ultimately finding what truly drives us.
This led to some powerful takeaways from the session, reminding us how we too can #accelerateaction in our own lives.
Here are some key takeaways from the session:
Take Risks to Discover Your Potential
One of the strongest messages from the session was the need to take risks. If we never step outside our comfort zones, we may never realize where our true potential lies.
Accelerate Action: Take Charge of Your Life
The theme #AccelerateAction isn’t just about movement – it’s about ownership. Our speakers highlighted that real change starts when we decide to take charge of our own lives. No one else can shape our future for us; we need to be the driving force behind our growth and transformation.
Work-Life Balance is Non-Negotiable
We tend to forget work–life balance at times but as our speakers indicated, work is a part of life, not our entire life. Achieving a healthy balance allows us to be more effective, engaged, and happy—both personally and professionally.
The Power to Create Change Lies Within Us
We tend to wait for external circumstances to improve, but actual change begins with us. Our speakers stressed that while challenges are inevitable, the power to adapt, evolve, and overcome lies within us.
Planning is the Key to Moving Forward
While action is important, planning is what makes it successful. Whether it’s in corporate, sports, or personal goals, having a structured plan helps in making informed decisions and staying focused on the bigger picture.
Listen: Inspiration is Everywhere
Often, we seek inspiration from books or podcasts, but we forget to listen to the people around us. We should pay attention to conversations, experiences, and stories shared by those in our daily lives—you never know who might inspire you in ways you never imagined.
In Tough Times, Create Space to Introspect
Life is not always according to plan, and we are bound to face setbacks. Instead of reacting impulsively, we should give importance to pausing, introspecting, and approaching problems with a calm mindset. Every challenge carries a lesson – accept it, learn from it, and move forward.
Focus on What’s in Your Control
In difficult situations, it’s important to distinguish between controllable and uncontrollable factors. Wasting energy on things outside our control only leads to frustration. Instead, we must channelize our energies toward what we can change and take purposeful action.
Accept Positive Criticism, Ignore Judgment
Feedback is essential for growth, but not all criticism is constructive. Our speakers advised keeping an open mind to positive criticism while filtering out unnecessary judgments that do not contribute to personal or professional growth.
This session was more than just a discussion – it was a powerful reminder to take action, take risks, and take control of our own lives. As we move forward, let’s embody the spirit of #AccelerateAction by making bold choices, embracing challenges, and continuously striving for growth.
Want to be part of a firm that fosters equal opportunities and an inclusive culture? Join us in creating a workplace where everyone thrives! Send us your resume at: careers@freshgravity.com.
Diversity, Equity, and Inclusion (DEI) in Technology and Consulting: A Point of View!
March 3rd, 2025 WRITTEN BY FGadmin Tags: DEI, Diversity, Equity, Inclusion

Written by Almas Jaipuri, Sr. Consultant, Data Science & Analytics, and Falguni Deswal, Analyst, Client Success
I, Almas Jaipuri, have been with Fresh Gravity for five years. During my interview, I was deeply impressed by the strong presence of highly influential women leaders in technical and management roles—a key factor in my decision to join the firm. Five years later, this commitment to diversity continues to grow, with women making up 40% of the workforce, 100% pay equity, and 50% of leadership positions held by women.
When I, Falguni Deswal, joined Fresh Gravity, I had no idea how enriching the experience would be. When I relocated to the Pune office, it was the first time I had stepped out of my comfort zone. However, from the moment I arrived, the support and encouragement from everyone was unwavering. My colleagues went above and beyond to help me settle in and their constant support made me feel included and valued at every step of the way.
This blog is a deep dive into our experiences at Fresh Gravity—experiences that have shaped our outlook towards the firm and have brought to light the diverse, inclusive, and talented pool of team members that have helped Fresh Gravity become a pioneer in the industry.
But first, let’s get the basics out of the way.
What is DEI and what does it include?
Diversity, Equity, and Inclusion are three distinct, yet interrelated concepts that are fundamental to creating a positive work environment.
- Diversity refers to the presence of differences in the workplace, encompassing a wide range of factors such as gender, race, ethnicity, religion, language, age, marital status, sexual orientation, physical/mental ability, socio-economic status, and even cultural perspectives. It’s about bringing together individuals with diverse backgrounds, each contributing their unique experiences and viewpoints.
- Equity goes beyond equality by ensuring that all individuals have access to the same opportunities. It involves recognizing that people have different needs and, therefore, may require different support structures to achieve equal outcomes.
- Inclusion is about creating an environment where everyone feels valued, respected, and supported. It’s about making sure that diverse voices are heard and that individuals are not only present but also actively participate and thrive within the organization.
At Fresh Gravity, we proudly foster an environment that embraces gender diversity, intergenerational equity, interdisciplinary inclusivity, and the absence of organizational hierarchies, regional dominance, or any other sectional biases.
When I (Almas) set out to pursue my ambition of moving overseas, Fresh Gravity provided me with the incredible opportunity to join its North America-based team. This opened new professional paths and connections for me. My colleagues here went above and beyond to make me feel welcome; they even attended my wedding in Toronto and celebrated with the rest of the firm by sharing precious moments on our internal communication channels. This made my day truly special as we transcended social and geographical barriers.
From the very beginning, I (Falguni) felt empowered by my team at Fresh Gravity. I have never felt that my age or level of experience would limit my potential here. In fact, during my very first week, I was entrusted with managing a team of five and had the opportunity to directly engage with stakeholders. That responsibility boosted my confidence and solidified my trust in the team I was about to work with.
Since then, I’ve never hesitated to dive into firm-wide activities, and recently, I had the chance to share my thoughts on Why is Fresh Gravity the Best Place to Work. This wouldn’t have been possible without the incredible leadership and the welcoming, inclusive culture at the heart of the firm.
How does Fresh Gravity promote DEI?
At Fresh Gravity, we are committed to fostering a diverse, equitable, and inclusive environment in all aspects of our work. Here’s how we integrate DEI into our practices:
- Unconscious Bias Training: We offer necessary trainings through our HR & Training platforms to raise awareness of unconscious bias and provide actionable steps to address it, ensuring that bias doesn’t impact our team in their decisions or interactions.
- Diverse Recruitment Partnerships: Our recruitment team actively collaborates with universities, coding boot camps, and organizations that connect underrepresented talent with tech opportunities. We also participate in job fairs specifically aimed at attracting diverse candidates, which helps expand our talent pool. We take a proactive approach in engaging candidates from various backgrounds and ensure that our job descriptions are inclusive.
- Women in Leadership: We’re proud to have a significant representation of women in leadership and executive roles, demonstrating our commitment to gender diversity at all levels of the organization.
- Support for Working Mothers: We provide strong support for women throughout their motherhood journey with a 26-week maternity leave and flexible work hours to help them transition back to work at their own pace. Don’t believe us? Hear from a new mom at Fresh Gravity about her experience.
- Global Inclusivity: To ensure our team is diverse and inclusive of different regions, we offer work-from-home options, allowing us to tap into talent from all over the world while maintaining flexibility for our team members.
Through these initiatives and others, Fresh Gravity has achieved near gender parity and takes pride in fostering a genuine commitment to inclusive growth, without relying on enforced quotas.
Key Benefits of Our DEI Commitment
Our strong commitment to embracing diverse talents and creating an inclusive environment has generated many valuable outcomes such as –
- Empowered Decision Making: A diverse group of people brings different experiences and outlooks. This has helped us identify challenges and present unique solutions that have led to better decision-making.
- Improved Innovation and Creativity: A diverse team brings a variety of perspectives, leading to better problem-solving and more creative ideas. This diversity enables Fresh Gravity to be innovation-led and drive meaningful advancements in our industry.
- Enhanced Employee Satisfaction: An inclusive environment ensures employees feel valued and respected, boosting morale, engagement, and retention. This was reflected in our recent off-site event, which stood out as one of the most memorable and impactful company-wide events we’ve experienced.
- Better Recruitment, Talent Retention: Our top-notch recruitment team’s dedication to hiring the best talent through diverse channels has built a strong, multifaceted workforce. Many team members have grown and evolved with Fresh Gravity over the years, including me (Almas).
DEI is an Ongoing Journey
DEI is an ongoing journey, one that needs to be adopted every step of the way. At Fresh Gravity, DEI initiatives are not just a priority but are woven into the fabric of our daily operations, helping us cultivate a workplace where equity, inclusion, and a genuine sense of belonging thrive for every employee.
For the past 10 years, we’ve prioritized fair, unbiased recruitment, focusing on the qualifications and potential of each candidate.
Our commitment to providing equal opportunities drives our success and helps us build a team where everyone can thrive.
If you’re looking to join a company that genuinely values DEI and embraces it in all aspects of its culture, we’d love to hear from you! Please send your resume to careers@freshgravity.com and take the first step toward making an impact with us.
Data Strategy: Why It’s Essential
February 5th, 2025 WRITTEN BY FGadmin Tags: data management, data strategy, data-driven decision-making

Written by Arjun Chaudhary, Director, Data Management
Data is a key foundational pillar for any digital transformation and is often regarded as the new currency for strategic decision-making. For organizations aiming to harness their data as a strategic asset, developing a cohesive data strategy is essential to meet current and future needs. A well-defined and effectively executed data strategy enables businesses to transform data into actionable insights, driving long-term success.
A comprehensive data strategy extends beyond data collection, governance, storage, and compliance. It focuses on managing and maximizing the full potential of data to deliver meaningful value and insights.
A well-defined data strategy outlines a vision for transforming an organization into a data-driven organization. To realize this vision, organizations must effectively understand, access, and connect their data; leverage the latest data science tools and techniques; nurture data talent and skills; and establish robust, organization-wide practices for data governance, management, and policy oversight.
Why We Need a Data Strategy
- Recognizing Data as an Asset – In the digital age, data is a valuable asset that can drive insights, innovation, and decision-making. A data strategy ensures that data is treated as a strategic resource.
- Aligns with Business Goals – A data strategy aligns data initiatives with organizational objectives, ensuring that data efforts support and enhance business outcomes.
- Establishes Data Governance – It establishes data governance practices, including data quality, security, and compliance, to maintain data integrity and protect sensitive information.
- Increases efficiency – A data strategy streamlines data operations and reduces redundancies, leading to cost savings and operational efficiency.
- Data Monetization – It enables organizations to monetize their data assets by identifying opportunities for data-driven products or services.
- Competitive Edge – A well-executed data strategy can give a competitive edge by enabling data-driven decision-making, personalization, and predictive analytics.
Benefits of a Well-Defined Data Strategy
- Better Decision-Making – With a strong data strategy, organizations can make more informed, data-driven decisions by analyzing current and historical data.
- Competitive Advantage – Leveraging advanced data analytics allows companies to identify trends, optimize operations, and develop new products faster than competitors.
- Improved Data Quality – Data governance policies ensure higher data accuracy, consistency, and reliability across the organization.
- Regulatory Compliance – A data strategy that addresses compliance ensures that organizations adhere to legal frameworks like GDPR, HIPAA, or CCPA, reducing the risk of fines and penalties.
- Cost Optimization – Efficient data management and infrastructure can lead to cost savings by eliminating data silos, reducing storage costs, and optimizing resource usage.
- Enhanced Customer Experience – By using data to personalize offerings, optimize supply chains, and improve services, organizations can better meet customer needs and expectations
Developing a data strategy can be a complex and challenging endeavor. It’s important to recognize that creating and implementing a data strategy is not merely an IT project but rather a holistic, organization-wide process. Data strategy development should be inclusive, leveraging the organization’s priorities and expertise while fostering buy-in from key stakeholders.
As the data strategy takes shape, it should be formally articulated and published, at least for internal use. If it isn’t documented and shared, it ceases to be a strategy and becomes a secret. Lastly, organizations must be prepared to allocate the necessary resources to support both the data strategy and the infrastructure required to sustain it.
Building an effective data strategy hinges on establishing strong data management practices from the outset. Fresh Gravity’s Data Management Capability provides a solid framework to achieve this, serving as the cornerstone for transforming into a data-driven organization and crafting a resilient data strategy. To know more about our offerings, please write to us at info@freshgravity.com.
Building a Diverse and Inclusive Tech Team: A Pathway to Innovation and Success
January 22nd, 2025 WRITTEN BY FGadmin Tags: best work culture, culture, Diversity, inclusivity, innovation

Written by Sonali Kulkarni, Sr. Manager, People & Talent
In the fast-paced and competitive tech industry, companies are increasingly recognizing the importance of fostering diverse and inclusive teams. From its inception, Fresh Gravity has made this principle a cornerstone of its culture. Diversity is not just a buzzword for us —it is a powerful driver of innovation, creativity, and success.
Our diverse and inclusive team brings a wealth of perspectives, skills, and experiences, creating an environment where fresh ideas thrive. This has been achieved through a culture that celebrates and values differences, ensuring that everyone feels respected, heard, and empowered.
Here are some foundational elements that have contributed to building our diverse and inclusive team:
Leadership Commitment
Building a diverse and inclusive team begins with strong leadership. From the start, Fresh Gravity’s leaders have actively cultivated an inclusive culture, consistently setting clear diversity goals and holding themselves and their teams accountable for achieving them. Whether through hiring diverse professionals, offering trainings, or allocating resources, our leadership team has played a key role in establishing Fresh Gravity’s overall direction.
Our leaders are receptive to feedback from team members, ensuring that inclusion efforts are meaningful. Open, transparent communication is vital for understanding the challenges employees face and finding ways to address them. By prioritizing listening, our leaders make sure everyone’s voice is heard.
Expanding our Talent Pool
Our recruitment team is dedicated to building a diverse team by expanding their efforts beyond traditional channels. Relying solely on familiar networks and hiring practices can limit diversity. Hence, the recruitment team actively partners with universities, coding bootcamps, and organizations that connect diverse talent with tech opportunities. They also participate in job fairs focused on attracting diverse candidates to broaden the talent pool. The recruitment team takes proactive measures to engage candidates from various backgrounds and ensures that job descriptions are inclusive.
Fostering an Inclusive Culture
An inclusive workplace empowers employees to bring their authentic selves to work, confident that they will be respected for who they are.
We make sure that everyone participates in regular trainings on topics such as unconscious bias and imbibe company values and culture. This helps team members gain a better understanding of each other, fostering a more empathetic environment. We also encourage open communication and create safe spaces for individuals to share their thoughts, concerns, and suggestions.
Furthermore, we offer mentorship programs that support career growth while also nurturing a sense of belonging and community within the team.
Promoting Equal Opportunities for Growth
As a company, we are committed to building a diverse team with equal access to growth and advancement opportunities. We make career development and promotion pathways clear and transparent for everyone. Through training and development programs, we empower employees to enhance their skills, take on new challenges, and advance in their careers. We foster a feedback-driven culture where employees receive regular constructive input and support for their professional growth. This approach ensures that all individuals have an equal opportunity to succeed and progress within the company.
Encouraging Diverse Perspectives and Collaboration
We hire team members with different backgrounds and viewpoints to work together. Such talents can address problems from multiple angles, and this leads to more thorough, creative, and well-rounded solutions. Collaboration brings a variety of opinions and insights into the decision-making process, allowing teams to make more informed, well-considered choices. This collective approach ensures that biases are minimized and that the decisions reflect the needs of a broad customer base.
Our employees embrace diverse perspectives that tend to be more adaptable because they are accustomed to considering multiple viewpoints and responding to differing needs. This makes them more agile in addressing new challenges or changes in the market. At its core, innovation is about seeing things differently and finding new ways of doing things. Our diverse teams are naturally more innovative because they approach problems with a variety of strategies and ideas, resulting in breakthroughs that might not arise in more homogeneous groups.
Healthy relationships flourish when these principles are applied effectively. By being thoughtful and purposeful in our approach, we strengthen our connections and move toward growth more smoothly. This is what makes Fresh Gravity an excellent place to work.