.png)
Data and Databricks: Concept and Solution
January 25th, 2024 WRITTEN BY Saswata Nayak, Manager, Data Management Tags: data governance, data ingestion, data management, data migration, data processing, data quality, data quality management, data serving, data-driven decision-making, Industry-agnostic, modern data platform

Blog co-authors: Saswata Nayak, Manager, Data Management
As we stand at the most crucial time of this decade which is believed to be the “Decade of Data”, let’s take a look at how this generation of data is going to live up to the hype it has created. Be it any field of life, most decisions we make today are based on data that we hold around that subject. When the size of data is substantially small, our subconscious mind processes it and makes decisions with ease, but when the size of data is larger and decision-making is complex, we need machines to process the data and use artificial intelligence to make critical and insightful decisions.
In today’s data-driven world, every choice, whether made by our brains or machines, relies on data. Data engineering, as the backbone of data management, plays a crucial role in navigating this digital landscape. In this blog, we’ll delve into how machines tackle data engineering and uncover why Databricks stands out as one of the most efficient platforms for the job.
In a typical scenario, the following are the stages of data engineering –
Migration
Data migration refers to the process of transferring data from one location, format, or system to another. This may involve moving data between different storage systems, databases, or software applications. Data migration is often undertaken for various reasons, including upgrading to new systems, consolidating data from multiple sources, or moving data to a cloud-based environment.
Ingestion
Data ingestion is the process of collecting, importing, and processing data for storage or analysis. It involves taking data from various sources, such as databases, logs, applications, or external streams, and bringing it into a system where it can be stored, processed, and analyzed. Data ingestion is a crucial step in the data pipeline, enabling organizations to make use of diverse and often real-time data for business intelligence, analytics, and decision-making.
Processing
Data processing refers to the manipulation and transformation of raw data into meaningful information. It involves a series of operations or activities that convert input data into an organized, structured, and useful format for further analysis, reporting, or decision-making. Data processing can occur through various methods, including manual processing by humans or automated processing using computers and software.
Quality
Data quality refers to the accuracy, completeness, consistency, reliability, and relevance of data for its intended purpose. High-quality data is essential for making informed decisions, conducting meaningful analyses, and ensuring the reliability of business processes. Poor data quality can lead to errors, inefficiencies, and inaccurate insights, negatively impacting an organization’s performance and decision-making.
Governance
Data governance is a comprehensive framework of policies, processes, and standards that ensures high data quality, security, compliance, and management throughout an organization. The goal of data governance is to establish and enforce guidelines for how data is collected, stored, processed, and utilized, ensuring that it meets the organization’s objectives while adhering to legal and regulatory requirements.
Serving
Data serving, also known as data deployment or data serving layer, refers to the process of making processed and analyzed data available for consumption by end-users, applications, or other systems. This layer in the data architecture is responsible for providing efficient and timely access to the information generated through data processing and analysis. The goal of data serving is to deliver valuable insights, reports, or results to users who need access to the information for decision-making or other purposes.
How Databricks helps at each stage
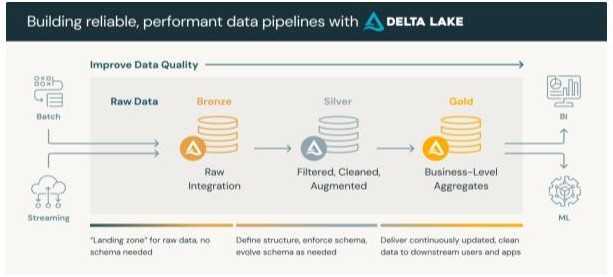
In recent years, Databricks has been instrumental in empowering organizations to construct cohesive data analytics platforms. The following details showcase how Databricks has managed to achieve this –
Migration/Ingestion
Data ingestion using Databricks involves bringing data into the Databricks Unified Analytics Platform from various sources for further processing and analysis. Databricks supports multiple methods of data ingestion, and the choice depends on the nature of the data and the specific use case. Databricks provides various connectors to connect and ingest or migrate data from different source/ETL systems to cloud storage and the data gets stored in desired file formats inside cloud storage. As most of these formats are open source in nature, later they can be consumed by different layers of architecture or other systems with ease. Autoloader and Delta live table (DLT) are some other great ways to manage and build solid ingestion pipelines.
Data Processing
Databricks provides a collaborative environment that integrates with Apache Spark, allowing users to process data using distributed computing. Users can leverage Databricks notebooks to develop and execute code in languages such as Python, Scala, or SQL, making it versatile for various data processing tasks. The platform supports both batch and real-time data processing, enabling the processing of massive datasets with ease. Databricks simplifies the complexities of setting up and managing Spark clusters, offering an optimized and scalable infrastructure. With its collaborative features, Databricks facilitates teamwork among data engineers, data scientists, and analysts.
Data Quality
Databricks provides a flexible and scalable platform that supports various tools and techniques for managing data quality. Implement data cleansing steps within Databricks notebooks. This may involve handling missing values, correcting errors, and ensuring consistency across the dataset. Include validation checks in your data processing workflows. Databricks supports the integration of validation logic within your Spark transformations to ensure that data meets specific criteria or quality standards. Leverage Databricks for metadata management. Document metadata related to data quality, such as the source of the data, data lineage, and any transformations applied. This helps in maintaining transparency and traceability. Implement data governance policies within your Databricks environment. Define and enforce standards for data quality and establish roles and responsibilities for data quality management.
Data Governance
Data governance using Databricks involves implementing policies, processes, and best practices to ensure the quality, security, and compliance of data within the Databricks Unified Analytics Platform. Databricks’ RBAC features control access to data and notebooks. Assign roles and permissions based on user responsibilities to ensure that only authorized individuals have access to sensitive data. Utilize features such as Virtual Network Service Endpoints, Private Link, and Azure AD-based authentication to enhance the security of your Databricks environment. Enable audit logging in Databricks to track user activities, data access, and changes to notebooks. Audit logs help in monitoring compliance with data governance policies and identifying potential security issues.
Data Serving
Data serving using Databricks involves making processed and analyzed data available for consumption by end-users, applications, or other systems. Databricks provides a unified analytics platform that integrates with Apache Spark, making it well-suited for serving large-scale and real-time data. Utilize Databricks SQL Analytics for interactive querying and exploration of data. With SQL Analytics, users can run ad-hoc queries against their data, create visualizations, and gain insights directly within the Databricks environment. Connect Databricks to popular Business Intelligence (BI) tools such as Tableau, Power BI, or Looker. This allows users to visualize and analyze data using their preferred BI tools while leveraging the power of Databricks for data processing. Use Databricks REST APIs to programmatically access and serve data. This is particularly useful for integrating Databricks with custom applications or building data services. Share insights and data with others in your organization. Databricks supports collaboration features, enabling teams to work together on data projects and share their findings.
In a nutshell, choosing Databricks as your modern data platform might be the best decision you can make. It’s like a superhero for data that is super powerful and can do amazing things with analytics and machine learning.
We, at Fresh Gravity, know Databricks inside out and can set it up just right for you. We’re like the sidekick that makes sure everything works smoothly. From careful planning to ensuring smooth implementations and bringing in accelerators, we’ve successfully worked with multiple clients throughout their data platform transformation journeys. Our expertise, coupled with a proven track record, ensures a seamless integration of Databricks tailored to your specific needs. From architecture design to deployment and ongoing support, we bring a commitment to excellence that transforms your data vision into reality.
Together, Databricks and Fresh Gravity form a dynamic partnership, empowering organizations to unlock the full potential of their data, navigate complexities, and stay ahead in today’s data-driven world.
If you are looking to elevate your data strategy, leveraging the power of Databricks and the expertise of Fresh Gravity, please feel free to write to us at info@freshgravity.com.




